2.
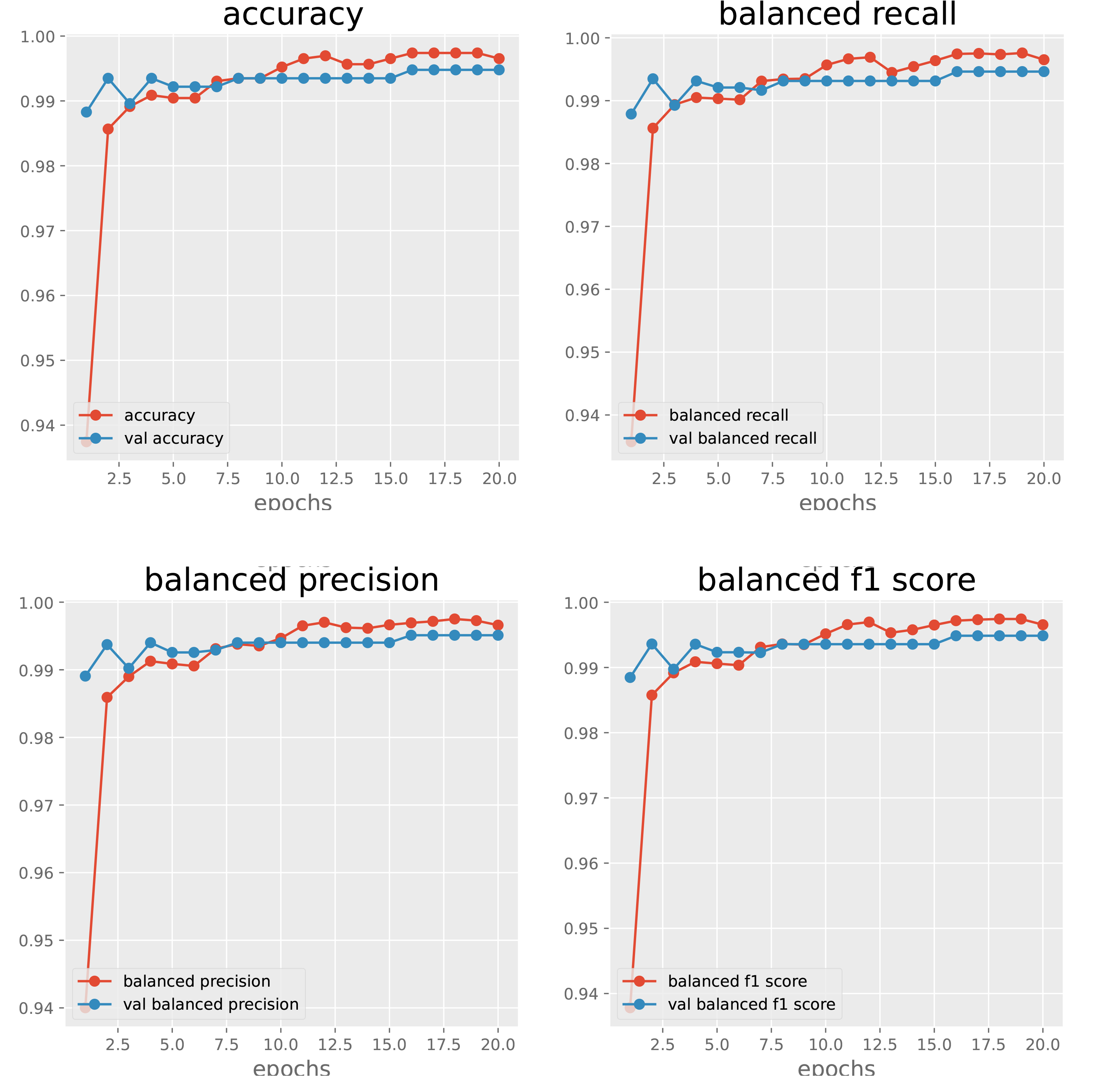
Figure 1: Model accuracy, recall, precision and f1 scores on the task of classifying climate fever sentences vs novel sentences.
As we also wanted to classify whether the fever sentences that we identified in novels were climate positive or negative, we also replicated Diggleman et al.’s study, training a separate Keras model on the climate fever dataset itself to differentiate between climate positive and climate negative sentences. Although not as robust as our fever vs novel model, our process still performed more than adequately with accuracy and f1 scores approaching 80% (Figure 2).
Figure 2: Model accuracy, recall, precision and f1 scores on the task of classifying supported vs refuted sentences.
2.1. Results
Our initial study classified all sentences from both corpora using our fever vs novel sentence model. As we predicted, the vast majority of sentences in both novels were classified as novel sentences, however, there were a non-trivial number of sentences in both corpora that were classified as belonging to the climate fever data set. More importantly, there is a large discrepancy between our two corpora, with over 4% of sentences in our CliFi Corpus classified as fever sentences vs 0.61% of the Chicago corpus (Figure 3). This indicates that Climate Fiction does incorporate far more real-world facts, particularly those about climate, than a random novel from the same period.
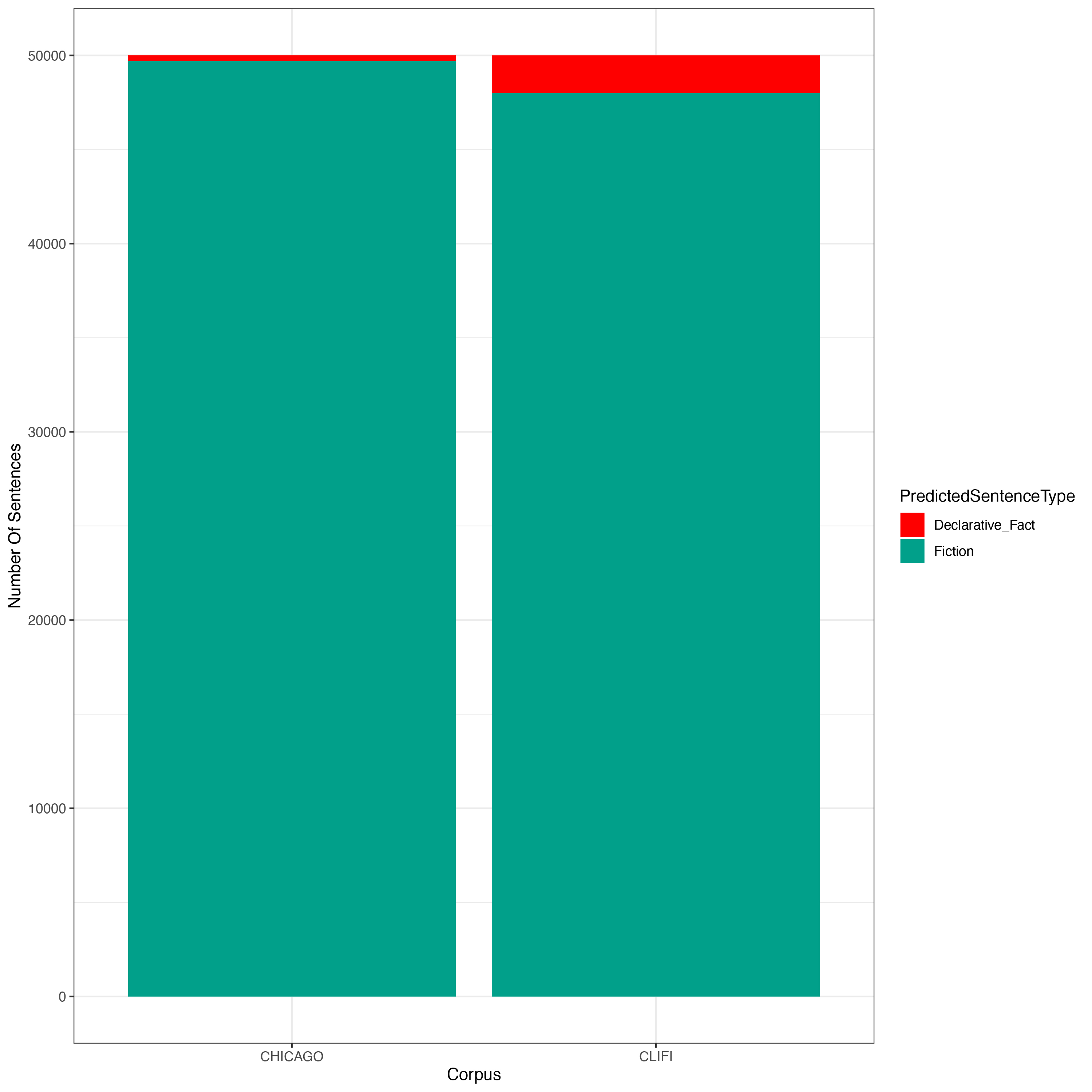
Figure 3: Number of sentences classified as novel (green) or fever (red) sentences in both the sampled Chicago corpus and the CliFi corpus (Wilcoxon Rank Sum Test p-value on the difference between corpora was ~2x10-16).
There was a similar discrepancy in our results for whether the fever sentences in novels are supported or refuted by climate science. Using just those sentences from both corpora that were classified as fever sentences, we then classified these using our second model as to whether they were predicted to be refuted or supported by climate science. Once again, there was a significant difference between our two corpora with a smaller, but still highly significant margin of sentences from the CliFi corpus classified as supported by the science vs those from the Chicago corpus (Figure 4).
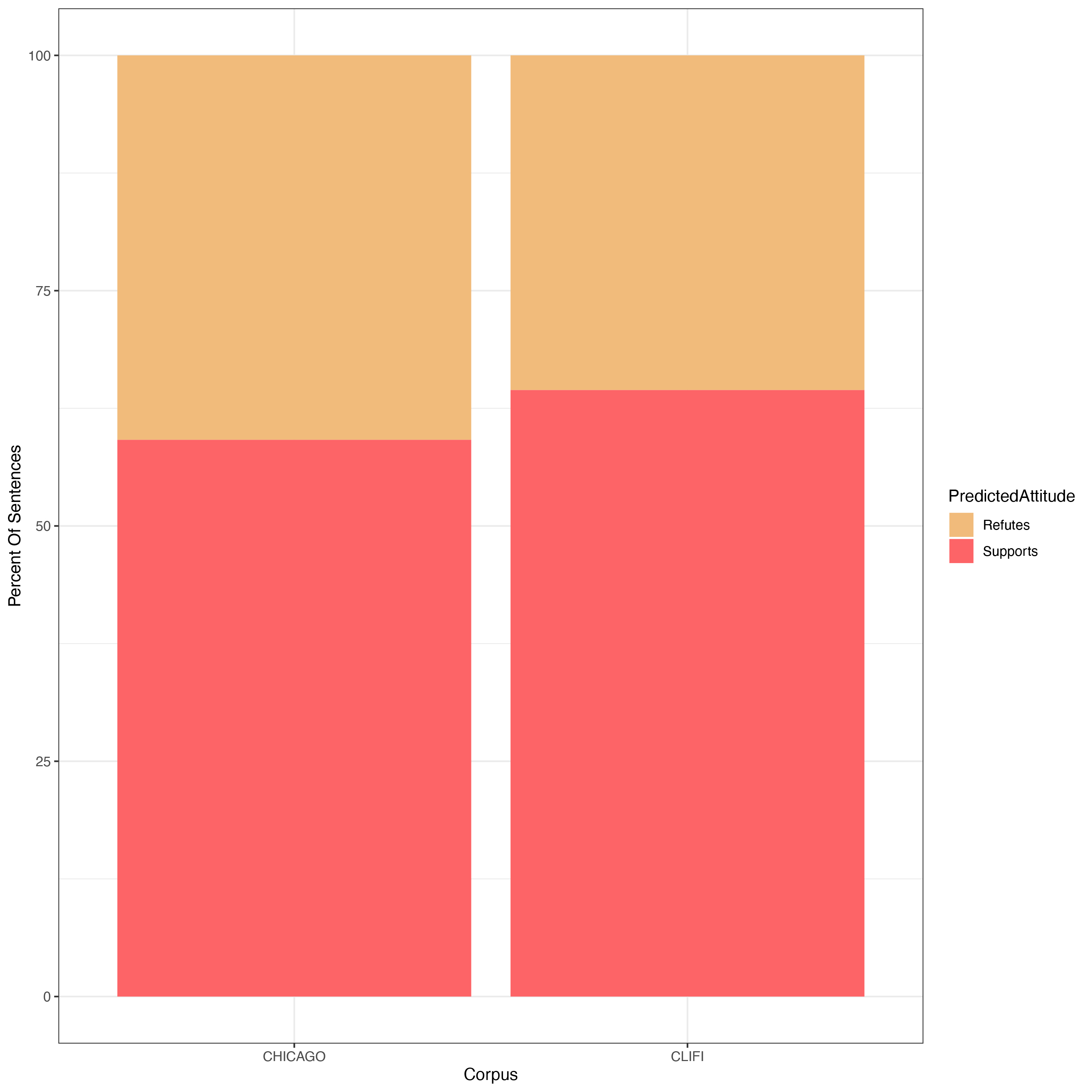
Figure 4: Percentage of fever-like sentences classified as supported (red) or refuted (yellow) in both the sampled Chicago corpus and the CliFi corpus (Wilcoxon Rank Sum Test p-value on the difference between corpora was ~2x10 -16).
As a final analysis, we selected a sample of novels from our CliFi dataset to close read for how the climate facts that the model discovered were embedded within the narrative. In addition to the literary analysis, we also tracked where in the narrative the fever-like sentences were located to see how facts were distributed within novels. In a surprising result, we discovered that climate fever-like sentences are not evenly dispersed throughout narratives, but instead occur within discrete segments (Figure 5).
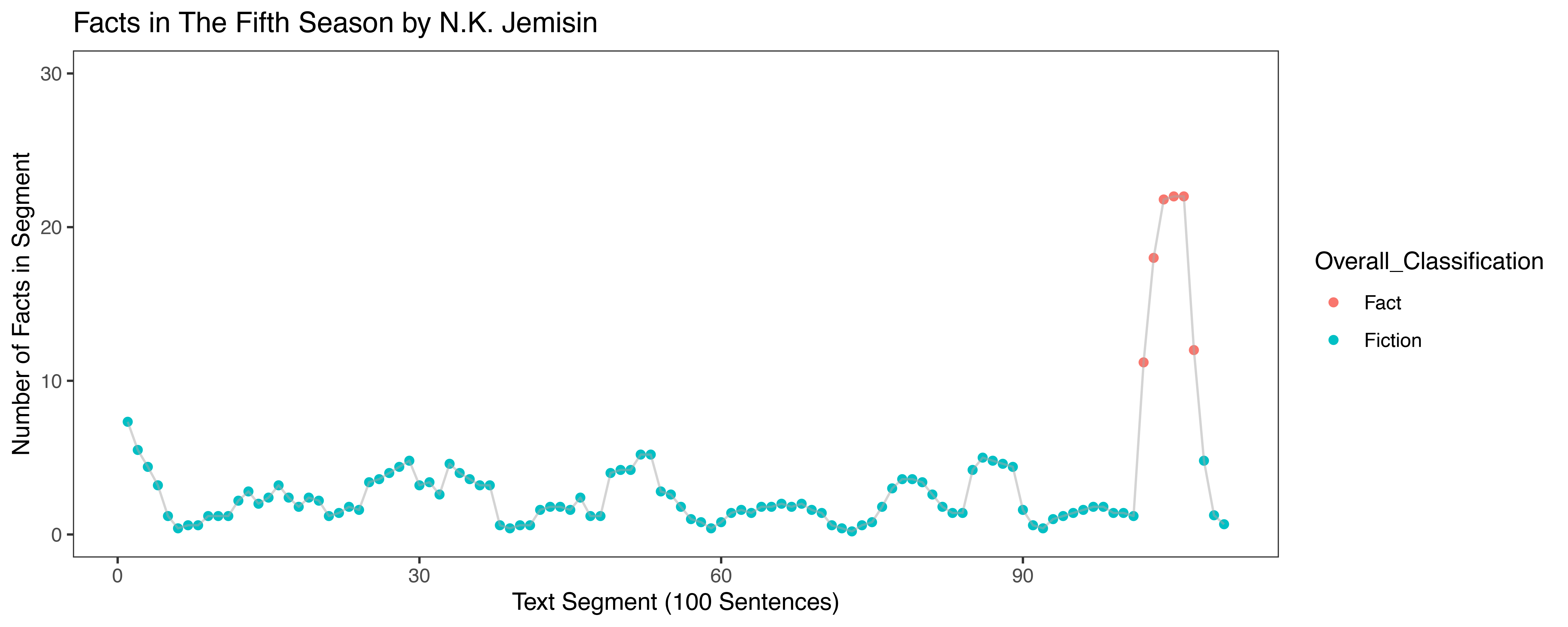
Figure 5: Raw number of climate fever-like (or fact) sentences per 100 sentence segments of Jemisin’s The Fifth Season. Red points indicate segments with a number of fever-like sentences more than 2 standard deviations above the mean.
Our results show that climate fiction is unique in its use of climate facts – both in terms of how many factual sentences are embedded within the fictional narratives, as well as in how many are “true” facts that are supported by current environmental science. Moreover, these facts are not arranged evenly throughout the narrative, but instead are grouped together at discrete points of the text. Taken together, these results indicate that climate fiction takes a unique approach to embedding many more “true” fact-based sentences within discrete parts of narratives as it seeks to teach its readers about the real-world dangers of climate change.