2. APPROACH
Story Dataset Collection: We collected two different datasets of short stories. One was gathered through crowdsourcing using commercial storytelling cards (see Figure 1) (Jang et al. 2023). The other was selected from a collection of flash fiction written by Kim Dong-sik, a Korean author renowned for his short stories with twist endings. Since 2018, Kim has published more than 300 pieces of flash fiction. Similar to Propp's 31 narrative functions in Russian folktales (Propp 1968), we defined 17 story units to analyze the structure of short stories with twist endings (Bae et al. 2023). These two story datasets were collected independently for different purposes: one for the emotional analysis of story patterns in English, and the other for the structural analysis of twisted-ending stories in Korean.
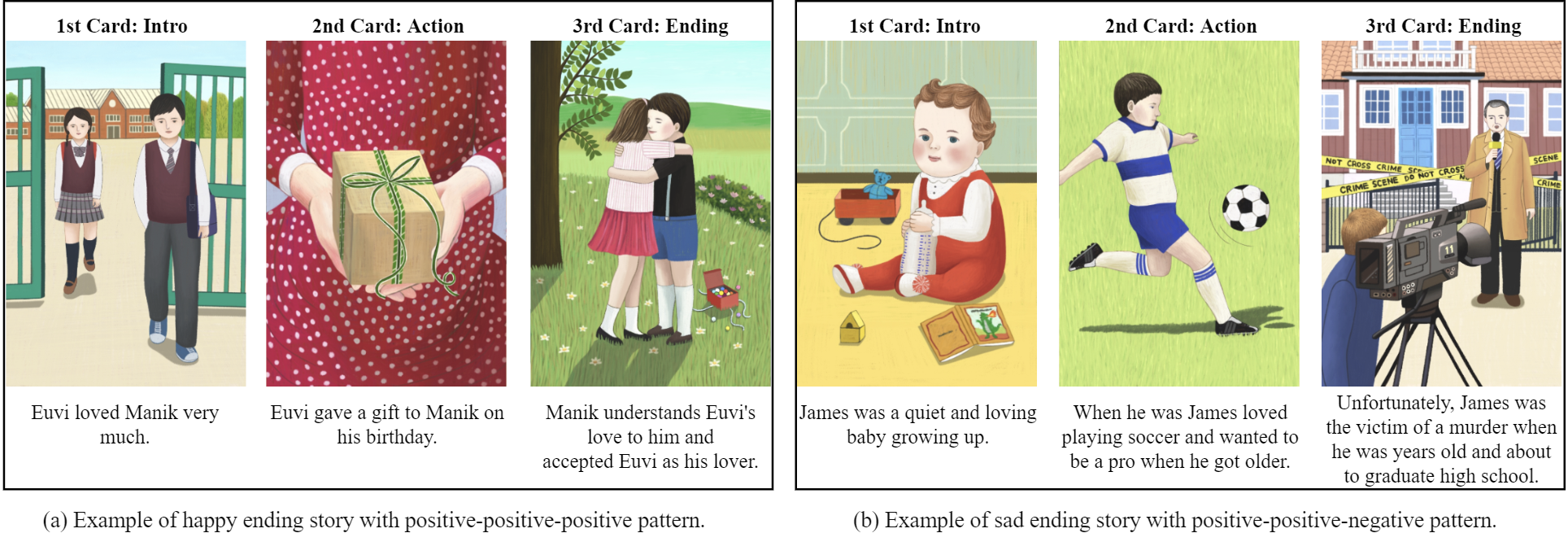
Dataset Analysis: First, we explore the sentiment patterns in a crowdsourced short story dataset, categorized by their ending type—either positive or negative (Jane et al. 2023). Furthermore, we annotate each story's level of interestingness and the contributing factors, such as detailed realism, humor, suspense, and plot twists, building upon our prior research on what makes stories interesting (Bae et al. 2021). Next, while examining Kim Dong-sik's flash fiction dataset, we introduce a new analysis method by annotating each story’s twist type, distinguishing whether it pertains to the plot or the character. Additionally, we assess the overall interestingness of each story.
Collaborative Writing Tool Design and Considerations: The widespread adoption of large language models (LLMs) has significantly influenced the development of human-AI "collaborative" story-writing systems, such as CoAuthor (Lee et al. 2022) and Wordcraft (Yuan et al. 2022), to support creative writing. While these LLM-based tools perform surprisingly well, they have evident limitations—for example, a lack of coherence in longer stories and the tendency to produce bland or clichéd events. Additionally, these tools bring up crucial issues, such as the need for new evaluation metrics and ways to measure the user's contribution.
Our paper introduces "interestingness" and its contributing factors as a new story evaluation metric. In our prototype writing tool, we consider narrative elements involving character arcs—whether positive or negative (Weiland 2016), myth-based character archetypes (Schmidt 2011), a story’s emotional arcs (Reagan 2016), master plot types (Tobias 2012), and Freytag’s 5-stage dramatic structure—exposition, rising action, climax, falling action, and denouement (Freitag 1895). Currently, we are working on combining our 17 story units for flash fiction with Freytag's 5-stage plot structure design.
Optimizing Language Models: Prompt engineering, such as CoT (Chain-of-Thought; Wei et al. 2022), or appropriate fine-tuning of large language models, can enhance the output. We are currently fine-tuning GPT-3.5-turbo with our annotated dataset and experimenting with various prompt formulas for improved results.