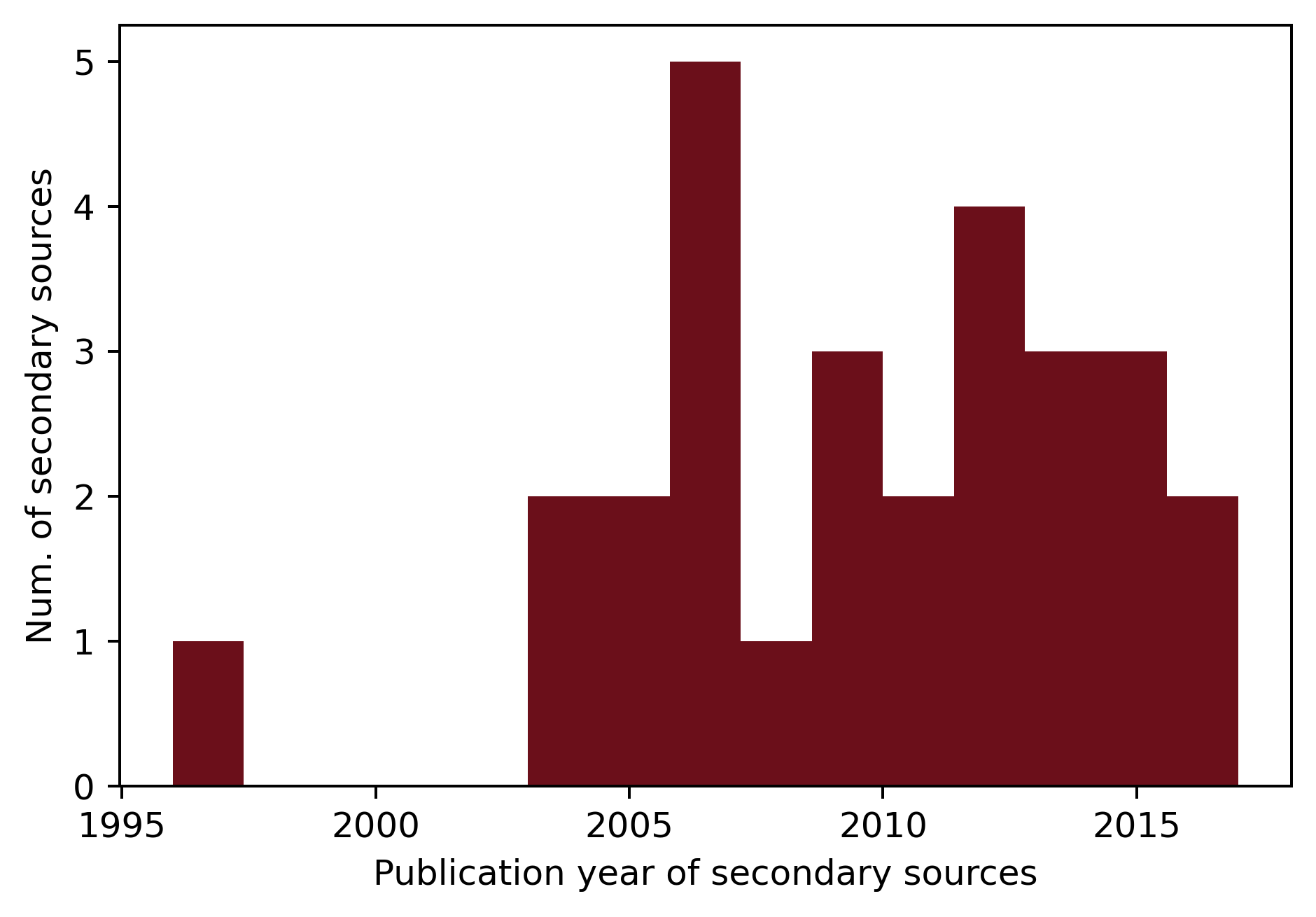
Figure 1. Distribution of publication years of secondary sources over years.
In computational literary studies, the exploration of literary history as a research subject has been primarily based on collections of historical literary works. These text corpora serve as the basis for identifying trends, common themes, stylistic structures, and topics, which are then juxtaposed with established literary historiographical narratives—sometimes corroborating, while at other times challenging them (Jockers 2013; Bode 2018). Some analyses have been expanded to incorporate what Bode refers to as "data-rich literary history" (2018: 37–57), encompassing metadata and traces of a text's "history of transmission" (2018: 38). Despite these advancements (Heuser 2016; Odebrecht et al. 2021; Schöch et al. 2022; Maryl et al. 2023), the integration of literary historiography as textual data remains less prevalent due to the difficulty of incorporating unstructured data into quantitative analyses.
The academic literary historical discourse is, however, an abundant source of data: Authors, genres, traditions, and literary texts are integrated in a resonating system of equation, comparison, and contrast. In an early examination of the possibilities of "computational historiography", Mimno (2012) demonstrates how a topic modeling approach to modern Classical scholarship can reveal trends in research topics. In other disciplines, word embeddings have proven to be useful for dealing with the "latent content" (Tshitoyan et al. 2019) of (academic) discourses: Wevers and Koolen (2020) show the utility of word embeddings in tracing semantic change of concepts in newspapers, Garg et al. (2018) employ word embeddings to quantify gender and ethnic stereotypes, and Tshitoyan et al . (2019) use them to explore and summarize the latent knowledge of material science. While similar applications are not as common in computational literary studies, word embeddings have been used to model literary characters (Bamman et al. 2014), identify patterns of intertextuality (Burns et al. 2021), examine gendered roles of characters (Grayson et al. 2017), and perform sentiment analysis (Jacobs 2019; Schöch 2022).
With these approaches in mind, this contribution outlines the steps necessary for the implementation of a word embedding of the academic literary historical discourse to quantify which authors and texts appear in similar contexts and presents first results of such an embedding covering the long 18 th and 19 th century of European Anglophone literary history. Given the importance of named entities for the aforementioned system of reference encoded in literary historical scholarship—especially persons and works of art—a fine-tuned named entity recognition (NER) was performed to generalize variations of entity names. In combination with an entity disambiguation using Wikidata identifiers, the NER process also ensures the compatibility of the extracted information with other data points structured as Linked Open Data (LOD).
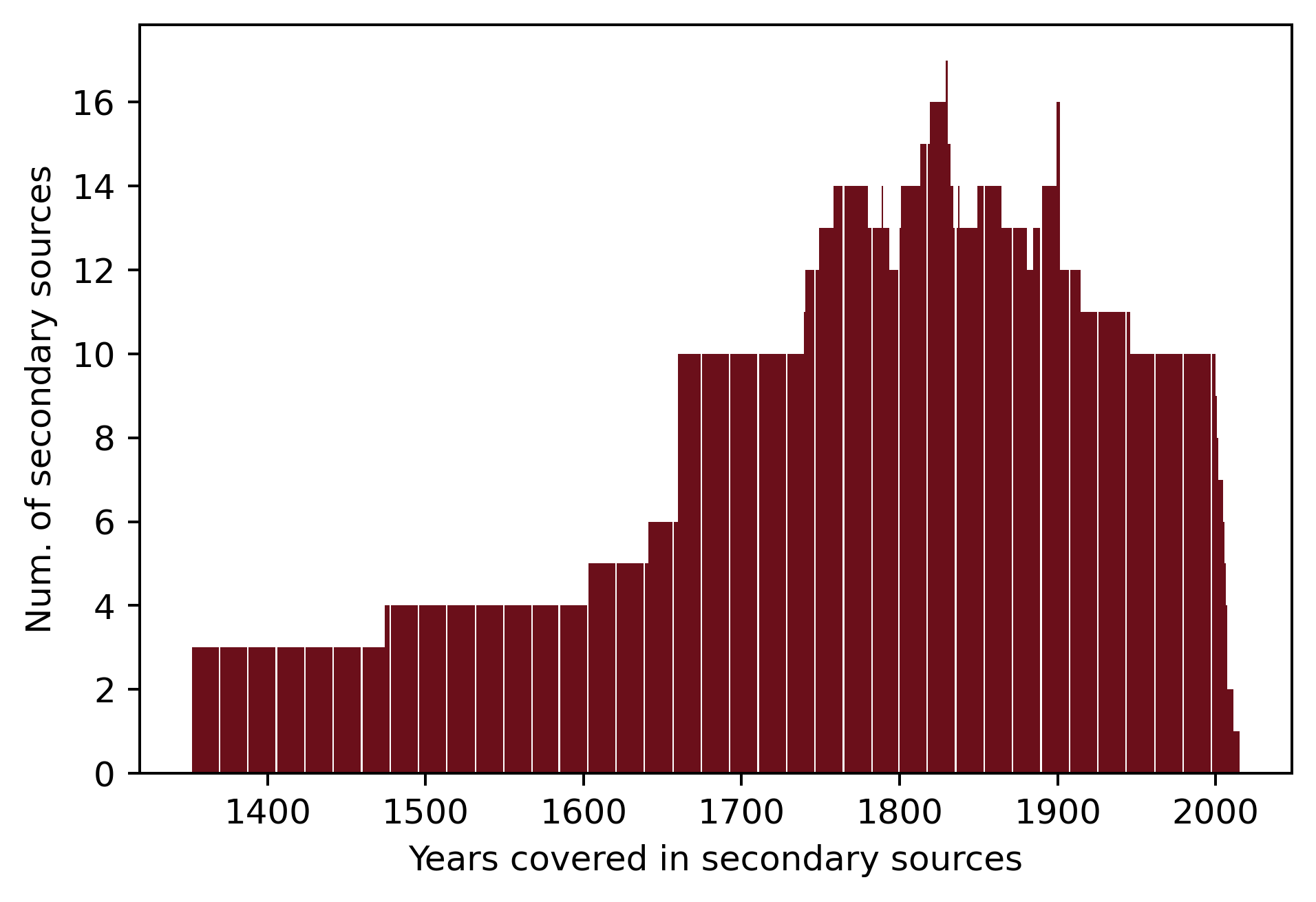
A corpus of 27 literary histories and companions to specific genres and literary periods was compiled. The secondary texts were chosen to represent different notions of canonicity—normative, academic, and the counter-canon—in order to cover a broad range of literary historical scholarship. As an additional prerequisite, only texts available in native PDF versions were used. The majority of texts were published between 2004 and 2017 (see Figure 1); the secondary texts analyzed thus represent a snapshot of recent literary historiographical scholarship. Figure 2 shows the periods of time covered in the respective literary histories as indicated by chronologies in front matters or by timeframes stated in introductions. On average, each literary history consists of 148,720 tokens, amounting to a total of 4.5 million tokens across the corpus.
To be able to compare and contrast how authors and texts are discussed and contextualized, their names and titles had first to be recognized with a fine-tuned spaCy (Explosion AI 2022) NER model. For this, the spaCy en_core_web_lg model was trained on a manually curated training data and tested on a gold standard, both taken directly from the corpus. With this kind of domain adaptation, the performance for both relevant labels, but especially for that of WORK_OF_ART, could be improved (see Table 1). The fine-tuned NER model was then used in combination with the spaCy entity fishing module (Lopez 2022), which extracts information for identified entities from Wikidata. The resulting pipeline produced text versions of the literary histories with entities replaced by unique identifiers consisting of capitalized versions of the entity names and, if applicable, Wikidata IDs (e.g., WILLIAM_SHAKESPEARE_Q692).
| spaCy en_core_web_lg | fine-tuned model | |||
| PERSON | WORK_OF_ART | PERSON | WORK_OF_ART | |
| p | 0.64 | 0.43 | 0.89 | 0.74 |
| r | 0.78 | 0.11 | 0.91 | 0.72 |
| f1 | 0.70 | 0.17 | 0.90 | 0.73 |
After an additional manual curation and correction of homonyms, the corpus was used as the basis for a word2vec embedding with 100 dimensions, a window size of 10, and a minimal count of 5 (Mikolov et al. 2013). The resulting word embedding allows for the calculation of the semantic similarity between each previously detected entity and every other entity encoded in the embedding. This enables the representation of entities based on their discussion in the academic discourse in a similarity network. Kruskal’s algorithm (1956) was used to filter the initially resulting hairball, revealing a so-called Minimum Spanning Tree (MST), a subgraph that ensures the connectedness of all nodes while pruning less significant edges.
As a representation of the "reference system" of literary history, this filtered network facilitates a meta-reading of literary historical discourse, enhancing accessibility through association: Lesser-known texts and authors can be explored through their connections with more canonical players in literary history. For quantitative text analysis, this means that network data based on this interconnectedness—such as similarities, clusters, and centrality measures—can be used as additional metadata, ensuring that even the analysis of lesser-known literary historical entities is context- and data-rich.