1.
Introduction
How can scattered information points in expansive historical documents be connected to provide meaningful insights? Situated in a project that explores themes of race and slavery throughout the first eight editions of
Encyclopaedia Britannica
(
EB
), 1768-1860, this paper focuses on a comparative network exploration of connections in slavery-related articles in the first and seventh editions, published in 1771 and 1842. Whilst the digitisation and availability of historical printed materials offers access to wider audiences
(Prescott and Hughes 2018)
, these sources convey knowledge produced, preserved and reinforced by our colonial legacies
(Gyebi-Ababio 2021)
. Consequently, there is a responsibility in DH to understand the relationship with knowledge production and our colonial past as we look to future work
(Risam 2015)
.
Whilst granting access to wider sections of our historical information environment, DH methods also offer the opportunity to explore and interrogate data at scale to foreground and understand biases
(Terras 2022: 260)
. This requires sustained exploration pushing the boundaries of the relationship between historians and technology
(Crymble 2021: 166)
to enable more comprehensive surveys of our historical sources. This research utilises network analysis as an exploratory tool to establish surface-level and hidden connections of enslavement within early editions of the
EB
to explore Enlightenment colonial legacies.
Previous historical research discussing race, slavery and national identity have referenced individual articles in specific editions
(Popkin 1974; Sebastiani 2013)
, however a comprehensive survey of race and slavery representations through the early
EB
has not been conducted. Whilst DH-oriented encyclopaedia projects have taken place in recent years
(Roe, Gladstone, and Morrissey 2016; Grabus et al. 2019)
, these have focused on textual functions rather than topic-focused diachronic surveys. This presentation uses
EB
’s structure (alphabetised articles, cross-references and indexes) to understand how slavery was represented, and where
EB
editors and contributors placed significance in linking information around race and slavery.
2.
Methods
A combination of text mining and data visualisations have been explored as a facilitator for effective historical research, and identified as a crucial starting point in guiding further enquiry and discussion
(Hinrichs et al. 2015: i73)
. This approach of creating network visualisations from mined text was employed to uncover slavery connections and guide a closer reading of the selected editions. The availability of these machine-readable datasets was crucial in enabling this research. The first edition text was created by the author using images from the National Library of Scotland’s Data Foundry (National Library of Scotland 2019)
with Handwritten Text Recognition Software Transkribus
(READ-COOP 2024)
to generate a text output of 2,419,807 tokens across three printed volumes. The seventh edition from the Nineteenth Century Knowledge Project
(Logan 2023)
was used, totalling 21,774,628 tokens representing nineteen physical volumes.
A pre-determined list of race and slavery-related keywords forms the basis of the analysis, focusing broadly on mention of people or organisations, geographic locations, or commodities associated with the transatlantic slave trade. These keywords, selected in dialogue with a historian of enslavement, were used to establish explicit and implicit mentions of these topics across
EB
editions. Explicit links had three main points of focus: firstly where keywords corresponded to article headings and which (if any) cross-references were made in these articles. Secondly, which articles these keywords occurred in as cross-references in the format ‘See SLAVE’. Thirdly, for keywords appearing as index topics, which articles they guided readers to.
Implicit links, those existing beyond the formal referencing structure of
EB
, were found in the occurrence of keywords throughout the text in the main body of the articles. All results were gained through keyword and cluster searches using AntConc
(Anthony 2023)
and compiled into CSV formats compatible with the open-source network visualisation software Gephi
(Mathieu Bastian 2009)
. Network graphs connecting the articles containing explicit and implicit links were generated with Gephi, providing visual networks of connections in the text to identify and explore further lines of enquiry.
3.
Results
The resulting network analysis visualisations yield new insights into enslavement in the early
EB
editions. Mapping connections between explicitly topic-relevant articles and those linked with cross-references shows a sparse collection with limited links between articles on commodities cultivation, production or manufacture, and geographic areas with slavery links. By comparing where slavery-related information is formally referenced versus where there are mentions throughout the text, we see there is extensive information on this topic that would not be discoverable and linkable through traditional historical research methods due to the text scale.
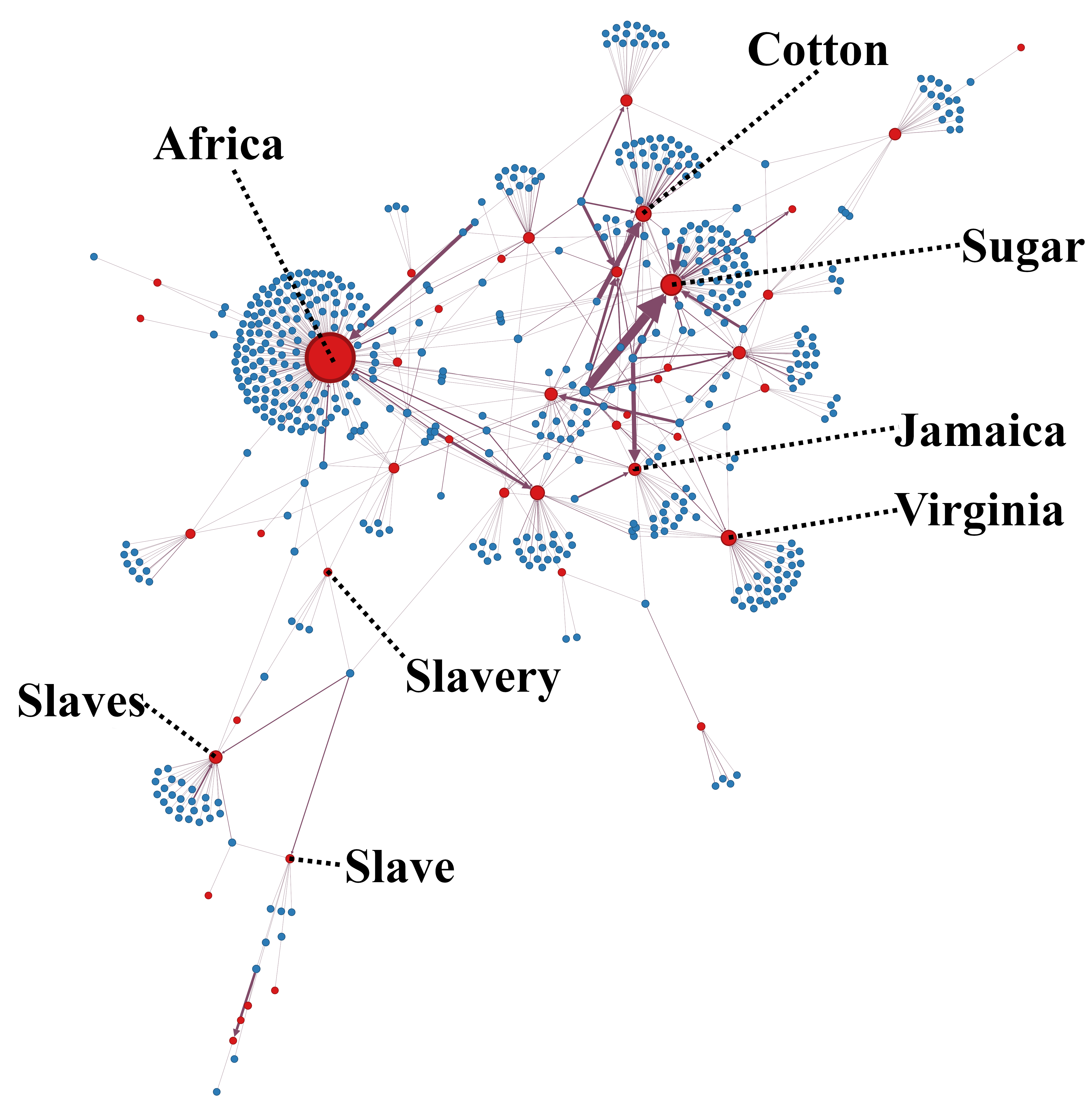
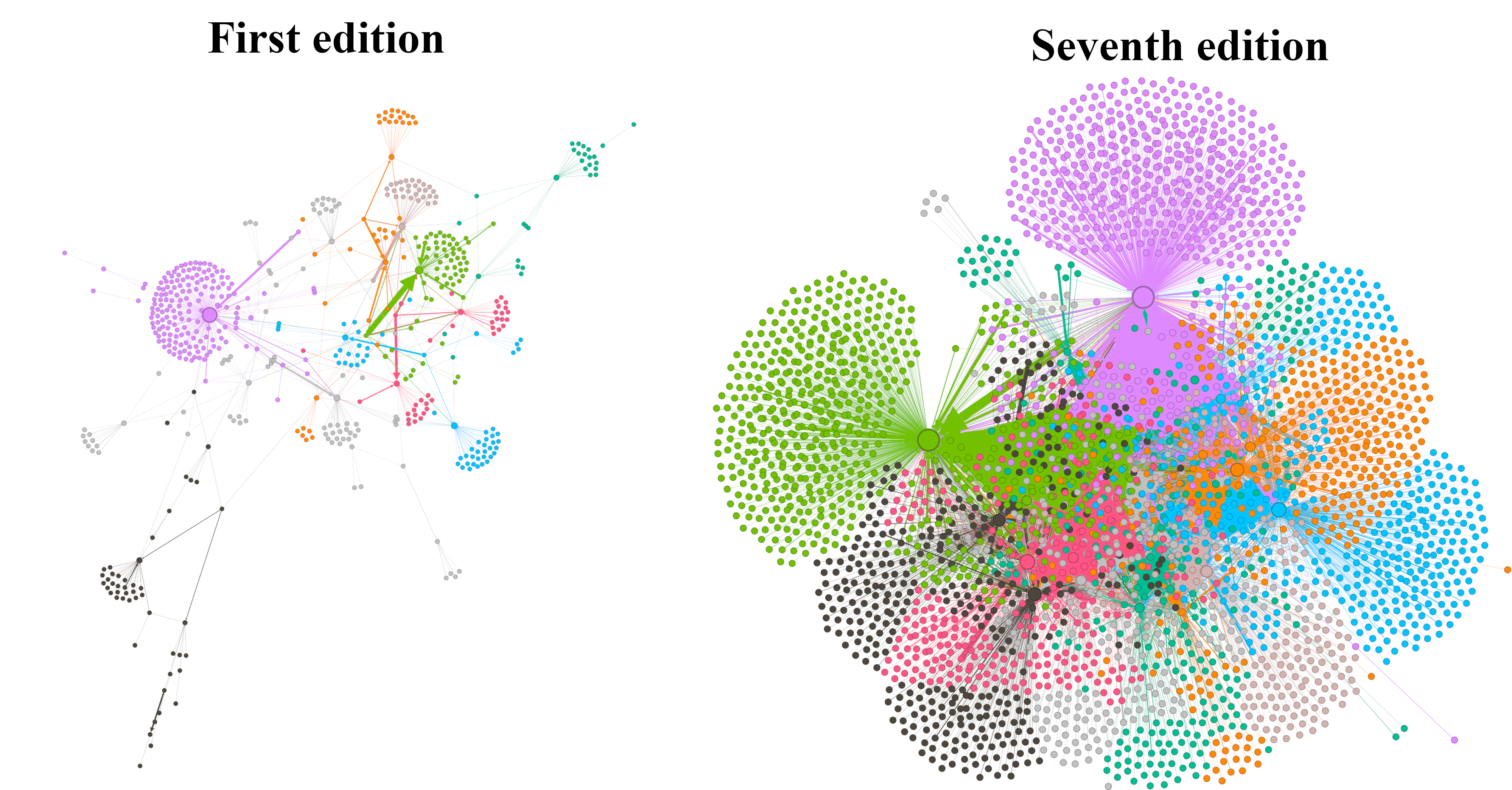
Figure 1 shows connections between nodes representing 48 keywords and the 544 articles they appear in. The thickest central arrow shows that the word ‘sugar’ features prominently in the ‘Medicine’ article, and yet is not connected to the ‘Slave’ article, therefore not making direct connections between the commodity and production labour. Equally, there is a high number of articles that mention Africa, yet direct links between slavery and the continent are absent. Using modularity metrics for community detection enables the discovery of eighteen communities of densely connected nodes in the first edition and ten for the seventh, useful in identifying patterns in connected keywords across larger datasets (see figure 2).
Whilst visualisations help categorise and represent well-established information in our historical knowledge bases (such as frequent mentions of cotton and sugar), following these keyword-article links allows for ‘hidden’ information across the text to be explored and the evaluation of omitted information on enslavement. Explicit mentions of ‘slaves’ in the first edition are largely rooted in ancient history contexts in articles such as ‘Alligati’, ‘Gladiators’ and ‘Saturnalia’. This trend continues in the seventh edition, but with increasing explicit discussions of contemporary slavery, commodities and geographic articles. These are still in veiled terms that often do not fully convey the extent of the transatlantic slave trade and European and American colonialist expansion that was occurring during this period. What lies beneath the surface of
EB
editions is an expansive breadth of information not incorporated into the explicit reference-driven knowledge networks, thus providing the opportunity to explore and challenge the colonial histories in this historical print environment, requiring connections mapping to interrogate this area with targeted close analysis.
4.
Conclusion
In 2019 Loveland claimed that a quantitative and digital humanities approaches to encyclopaedia studies “holds promise”, but deferred that computational capabilities “remains limited”
(Loveland 2019: 13)
. Our presentation demonstrates the aptitudes and value of using DH methods in encyclopaedia studies to answer novel questions about our historical information environment and draw on connections inaccessible to the traditional historian when examining large scale datasets. Whilst visualising the extensive network of keywords within articles demonstrates where links can be drawn between articles, the crucial result of this research is using the networks to identify silences within the text and where references to enslavement are absent. This approach creates a replicable process for investigating, visualising, and raising further questions on subjects in encyclopaedias and structured historical reference publications that can be applied beyond enslavement research.