1.
Introduction
Existing copyright law in the European Union, the United States of America and many other jurisdictions around the world means that Text and Data Mining (TDM) encounters several limitations concerning the storage, publication, and re-use of datasets derived from copyrighted texts. As a response, derived text formats (DTFs), also known as extracted features for non-consumptive research, have been proposed and used (see e.g. Rehm et al. 2007, Lin et al. 2012, Jett et al. 2020, Schöch et al. 2020). The core concept is to selectively remove specific pieces of information, particularly copyright-relevant features, from in-copyright texts. Put simply, such texts cannot be read by people, so that making them available to the public does not violate copyright law. At the same time, the texts are still suitable for a variety of TDM tasks in digital humanities (DH), such as authorship attribution or topic modeling.
There appears to be a trade-off between usefulness for research and safe use with respect to copyright. To better understand this and define DTFs that lie at a sweet spot combining usefulness for research and safety from a copyright perspective, a series of evaluations is needed. More precisely, the impact of information loss caused by DTFs on the performance of different TDM tasks must be assessed. In this work, we focus on evaluating two token-based DTFs on a common task in DH, namely BERT-based sentiment classification.
In the following, we first provide some earlier work (section 2), then describe the dataset and our method (section 3 & 4) before describing and discussing the results (section 5).
2.
Background
Text data with noise due to processes such as OCR is quite common and there are many studies address its impact. In stylometry, Eder 2013 and Büttner et al. 2017 have shown a certain robustness of distance-based methods against noise. In computational linguistics, recent studies have shown that pretraining with scrambled text appears to have little effect on BERT-based classifiers (e.g. Pham et al. 2020, Sinha et al. 2022, Abdou et al. 2022). Such studies used scrambled text to pretrain and to fine-tune language models, while testing the language models on exist benchmarks such as GLUE (Wang et al. 2019).
In fact, converting text to derived formats could be seen as creating and using noisy text data on purpose. However, the application and evaluation of DTFs in DH differs to some extent from research as described above. In DH, most researchers focus on a particular domain of texts, such as 20th century French popular fiction. When they want to use a language model to assist their study, instead of collecting a very large amount of text to pretrain an entirely new model, a more realistic alternative is to collect a smaller amount of text in the same domain to fine-tune an existing pretrained model and use it for further analysis. However, it could be difficult to get published text data in this domain if they are protected by copyright. Based on the research on scrambled text and language models, it is reasonable to assume that a BERT-model will also do well in downstream tasks like sentiment analysis after fine-tuning with DTFs. This means that copyrighted texts could be published as DTFs for model fine-tuning, while of course also being useful for other typical DH-tasks (see e.g. Behnk et al. 2014, Du 2023). To verify this, this study focuses on evaluating two token-based DTFs in a BERT-based sentiment classification task.
3.
Data
For the evaluation, we used two datasets. The first is a non-literary English corpus, the IMDb dataset, which contains positive and negative movie reviews. The aim was to test how well the sentiment classification works on simpler texts in DTFs. The second is a literary German corpus, the childTale-A dataset, which comprises eighty fairy tales by the Brothers Grimm and contains sentences manually labeled into three classes (positive, neutral, and negative; Herrmann & Lüdtke, 2023).
We used two kinds of DTF. The first (DTF-1) involves the removal of word sequence information through word order randomization. The second (DTF-2) selectively reduces the amount of information associated with individual tokens by replacing a certain proportion of randomly selected words with their corresponding Part-of-Speech (POS) tag. Table 1 illustrates the DTFs using an IMDb review in its original format alongside the derived formats.
| original text |
Sherlock Holmes took his bottle from the corner of the mantel-piece and his hypodermic syringe from its neat morocco case. With his long, white, nervous fingers he adjusted the delicate needle, and rolled back his left shirt-cuff. |
|
DTF-1
(randomized word order)
|
his bottle from of mantel-piece With his syringe from its the neat case. His white, took the fingers he and hypodermic Sherlock the Morocco delicate needle, and nervous corner rolled back his left shirt-cuff. Holmes long, adjusted |
| DTF-2 (50% of words replaced by POS tags) |
Sherlock PROPN VERB his NOUN from DET corner of the NOUN-piece CCONJ PRON hypodermic NOUN ADP its ADJ morocco case. ADP his long, ADJ, ADJ NOUN he VERB the delicate NOUN, CCONJ rolled ADV his left shirt-NOUN. |
Table 1. A text passage in different formats.
4.
Method
To conduct the evaluation, the texts were transformed into DTFs and then used to fine-tune DistilBERT (Sanh et al. 2019). After fine-tuning, the model’s performance was tested using a separate set of texts in their original form. Given the variability introduced by random processes, each test was repeated multiple times. Table 2 details the test conditions.
|
dataset |
training data |
validation data |
testing data |
runs |
| Test 1 |
IMDb
1
|
1000, DTF-1 |
400, DTF-1 |
400, original |
50 |
| Test 2 |
IMDb |
2000, DTF-1 |
400, DTF-1 |
400, original |
50 |
| Test 3 |
IMDb |
4000, DTF-1 |
400, DTF-1 |
400, original |
50 |
| Test 4 |
IMDb |
4000, DTF-2 |
400, DTF-2 |
400, original |
50 |
| Test 5 |
childTale-A
2
|
2100, DTF-1 |
900, DTF-1 |
900, original |
10 |
| Test 6 |
childTale-A |
2100, DTF-2 |
900, DTF-2 |
900, original |
10 |
Table 2. Detail of test conditions.
Comparing the classification performance of DistilBERT as fine-tuned on original texts versus DTFs shows the impact of DTFs on the model. Therefore, we also conducted a sentiment classification where DistilBERT was fine-tuned using original texts. Table 3 shows the results.
|
1000 IMDb reviews |
2000 IMDb reviews |
4000 IMDb reviews |
1200 fairy tale sentences |
| DistilBERT |
0.81 |
0.86 |
0.89 |
0.57 |
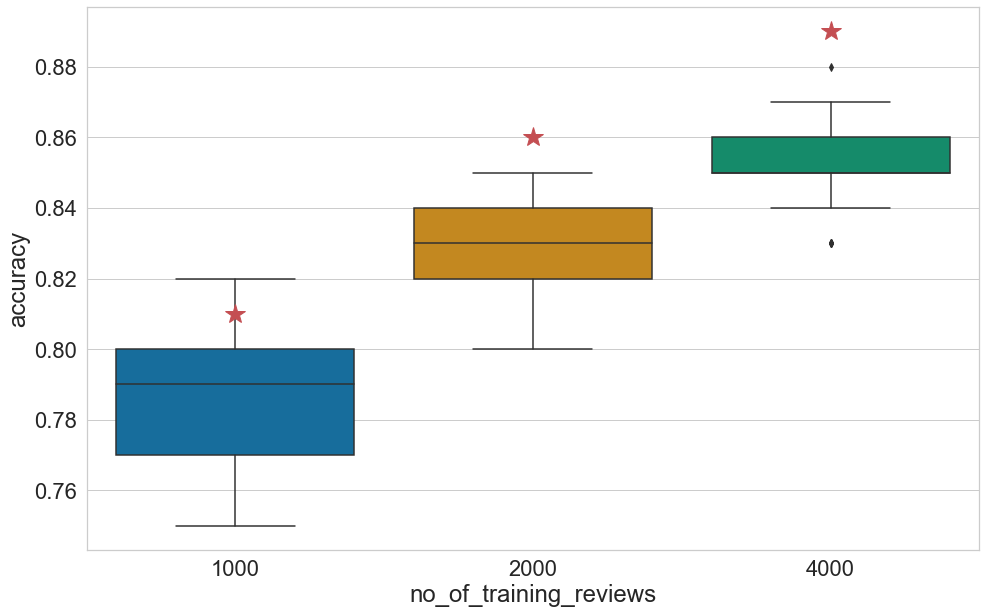
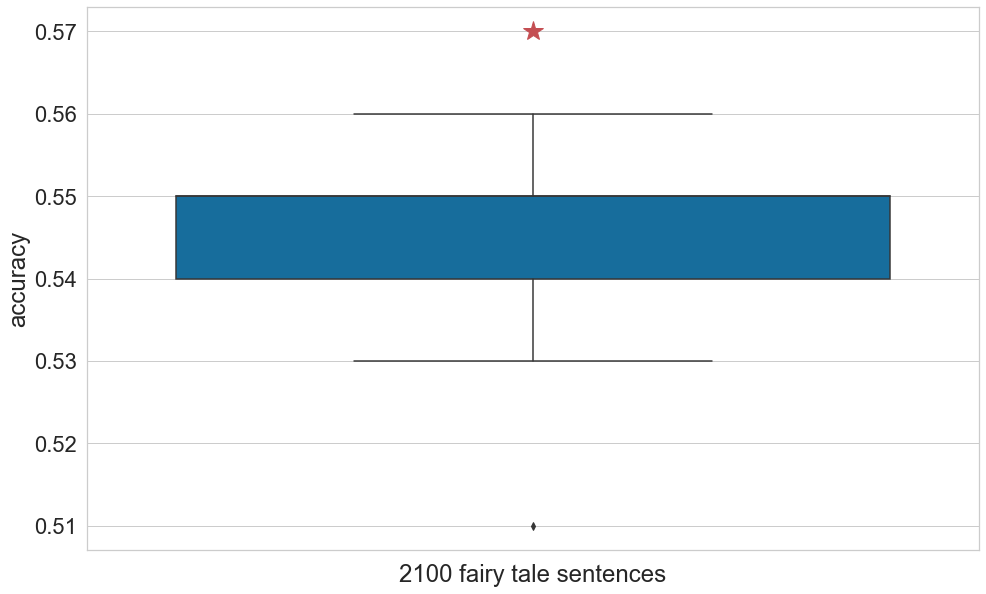
Table 3. Accuracy obtained as baselines for classifying the two datasets (Represented by red stars in Figures 1 and 3).
5.
Results
Figure 1 presents the classification results of tests 1–3 and the average accuracy is 0.79, 0.83 and 0.85, respectively, when DistilBERT was fine-tuned with 1000, 2000 and 4000 reviews, that is, moderately lower than the baselines. More training data leads to better classification results, as in the baselines, but the variance also decreases, indicating greater consistency and stability of the model.
Figure 1: Classification results in tests 1–3.
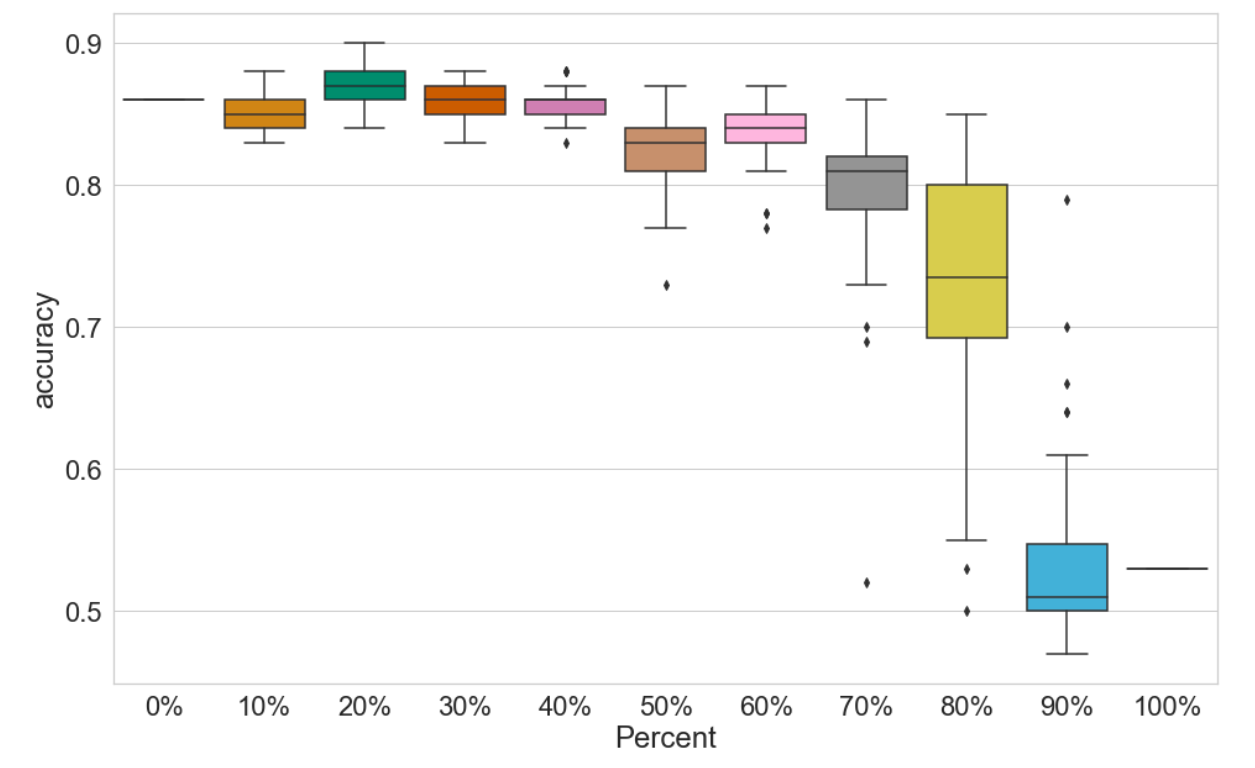
Figure 2 presents the classification results of test 4. The lines positioned at 0% and 100% represent performance when no words or all the words are replaced, respectively. The remaining nine boxplots each show the distribution of 50 accuracy scores. As expected, replacing more words with POS while fine-tuning the model leads to a decline in classification accuracy. Surprisingly, however, this decrease in accuracy is not linear. Models fine-tuned on texts with 10% to 40% POS tag proportions achieve similar classification results compared to the 0% scenario. Accuracy starts to decline only at 50% and 60%, with the most significant drop occurring between 80% and 90%.
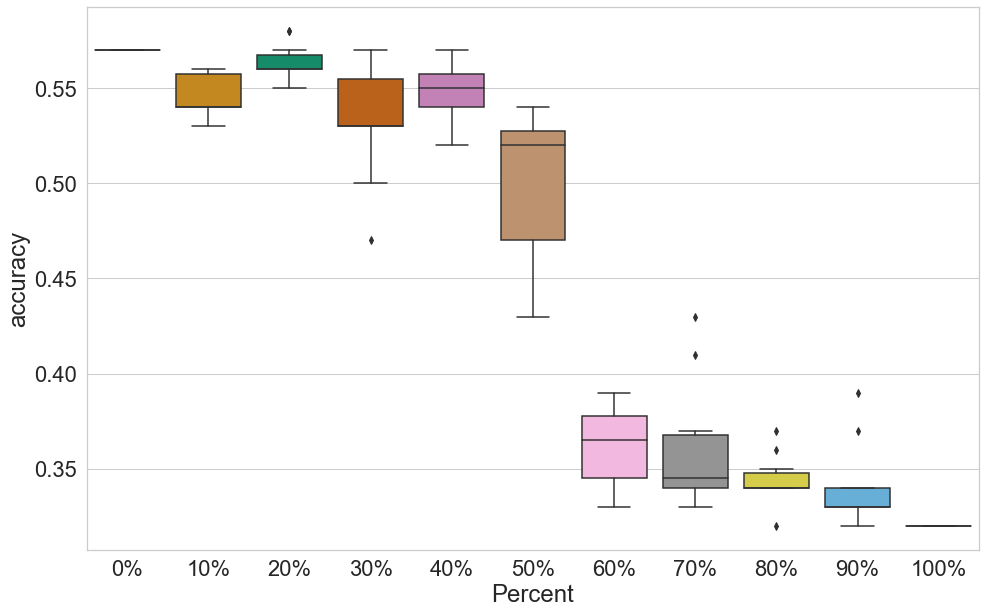
Similarly, the classification results on literary texts also suffered a noticeable, but by no means dramatic, loss because of DTF. Figure 3 shows that accuracy for scrambled text is mostly between 0.53 and 0.56, against the baseline of 0.57. Figure 4 shows the same general trends for the fairy tales as observed for the reviews, but accuracy starts to decline dramatically at 50%, with a dramatic drop already at 60%.
Figure 2: Classification results in Test 4.
Figure 3: Classification results in Test 5
Figure 4: Classification results in Test 6.
6.
Conclusion and future work
We show that transforming in-copyright texts into two token-based DTFs is indeed useful. They can be made freely available and used, for example, for fine-tuning a BERT-model to perform sentiment classification. The accuracy of classification can be maintained, to some extent, as long as the reduction of information respects certain limits. When 40% of the tokens are replaced by POS tags, readability and recognizability are drastically-impaired, but sentiment classification performance is only marginally affected. Therefore, this could be considered a sweet spot for DTFs.
For future research, the evaluation of the effectiveness of these token-based DTFs in other TDM tasks, such as topic modeling or text reuse, is on the agenda. Ultimately, the goal is to identify DTFs and their parameters that represent a good balance between various kinds of information, e.g. word frequency, sequence information, content words and function words etc.
Appendix A
Bibliography
-
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, Brussels, Belgium. Association for Computational Linguistics.
-
-
Büttner, Andreas; Dimpel, Friedrich Michael; Evert, Stefan; Jannidis, Fotis; Pielström, Steffen; Proisl, Thomas; Reger, Isabella; Schöch, Christof; Vitt, Thorsten (2017). “»Delta« in der stilometrischen Autorschaftsattribution”. Zeitschrift für digitale Geisteswissenschaften. https://dx.doi.org/10.17175/2017_006.
-
Du, Keli. 2023. “Understanding the impact of three derived text formats on authorship classification with Delta”. Jahreskonferenz der Digital Humanities im deutschsprachigen Raum. Trier/Luxemburg. DOI:
https://zenodo.org/doi/10.5281/zenodo.7715298.
-
Eder, Maciej (2013). “Mind your corpus: systematic errors in authorship attribution”. Literary and Linguistic Computing, 28(4), 603–614.
-
Gupta, Ashim, Giorgi Kvernadze, and Vivek Srikumar. "Bert & family eat word salad: Experiments with text understanding." Proceedings of the AAAI conference on artificial intelligence. Vol. 35. No. 14. 2021.
-
Herrmann, Berenike & Lüdtke, Jana (2023). A Fairy Tale Gold Standard. Annotation and Analysis of Emotions in the Children's and Household Tales by the Brothers Grimm. Zeitschrift für digitale Geisteswissenschaften (ZfdG). DOI: 10.17175/2023_005.
-
J. Jett, B. Capitanu, D. Kudeki, T. Cole, Y. Hu, P. Organisciak, T. Underwood, E. Dickson Koehl, R. Dubnicek, J. S. Downie, The HathiTrust Research Center Extracted Features Dataset (2.0), 2020. URL:
https://wiki.htrc.illinois.edu/pages/viewpage.action?pageId=79069329.
-
Jacob Jett, Boris Capitanu, Deren Kudeki, Timothy Cole, Yuerong Hu, Peter Organisciak, Ted Underwood, Eleanor Dickson Koehl, Ryan Dubnicek, J. Stephen Downie (2020). The HathiTrust Research Center Extracted Features Dataset (2.0). HathiTrust Research Center.
https://doi.org/10.13012/R2TE-C227.
-
Koustuv Sinha, Prasanna Parthasarathi, Joelle Pineau, and Adina Williams. 2021. UnNatural Language Inference. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7329–7346, Online. Association for Computational Linguistics.
-
Mostafa Abdou, Vinit Ravishankar, Artur Kulmizev, and Anders Søgaard. 2022. Word Order Does Matter and Shuffled Language Models Know It. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6907–6919, Dublin, Ireland. Association for Computational Linguistics.
-
P. Organisciak, J. S. Downie, Research access to in-copyright texts in the humanities, in: Information and Knowledge Organisation in Digital Humanities, Routledge, 2021, pp. 157–177.
-
-
Schöch, Christof, Frederic Döhl, Achim Rettinger, Evelyn Gius, Peer Trilcke, Peter Leinen, Fotis Jannidis, Maria Hinzmann, and Jörg Röpke. 2020. “Abgeleitete Textformate: Text und Data Mining mit urheberrechtlich geschützten Textbeständen”. Zeitschrift für digitale Geisteswissenschaften. URL:
http://zfdg.de/2020_006.
-
-
Thang Pham, Trung Bui, Long Mai, and Anh Nguyen. 2021. Out of Order: How important is the sequential order of words in a sentence in Natural Language Understanding tasks?. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1145–1160, Online. Association for Computational Linguistics.
-
Vinciarelli, Alessandro. "Noisy text categorization." IEEE transactions on pattern analysis and machine intelligence 27.12 (2005): 1882-1895.
-
V. Sanh, L. Debut, J. Chaumond, T. Wolf, DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (2019). URL:
https://arxiv.org/abs/1910.01108. doi:10.48550/ ARXIV.1910.01108.
-
Y. Lin, J.-B. Michel, E. Aiden Lieberman, J. Orwant, W. Brockman, S. Petrov, Syntactic Annotations for the Google Books NGram Corpus, in: Proceedings of the ACL 2012 System Demonstrations, Association for Computational Linguistics, Jeju Island, Korea, 2012, pp. 169–174. URL:
https://aclanthology.org/P12-3029.
-
Yuri Lin, Jean-Baptiste Michel, Erez Aiden Lieberman, Jon Orwant, Will Brockman, and Slav Petrov. 2012. Syntactic Annotations for the Google Books NGram Corpus. In Proceedings of the ACL 2012 System Demonstrations, pages 169–174, Jeju Island, Korea. Association for Computational Linguistics.