2.
Methods
Dataset.
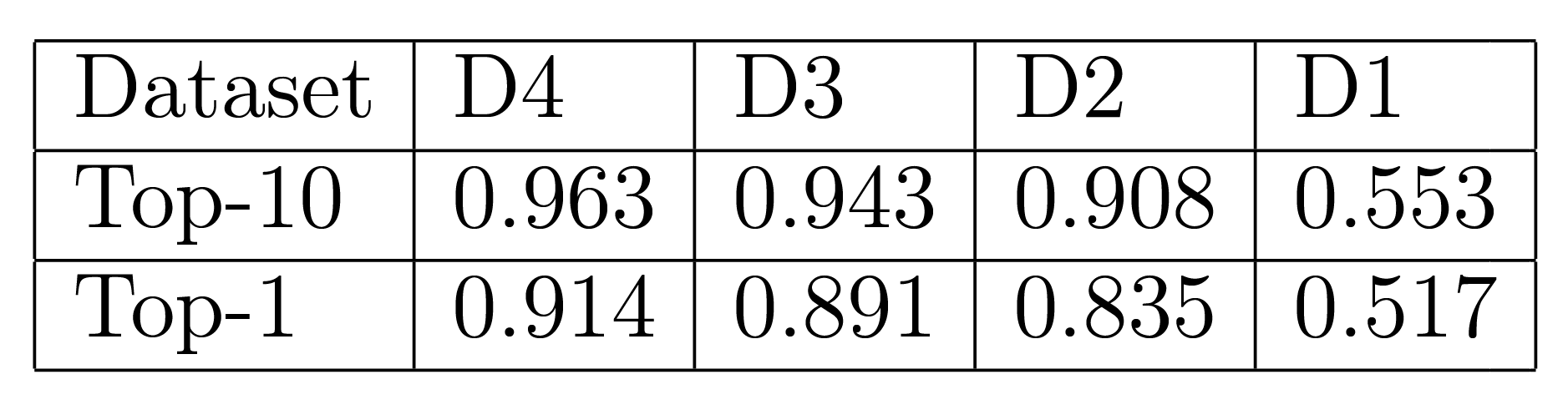
The National Institute of Japanese Literature created the ex-libris stamp dataset with 16619 entries. Each entry has metadata, a cropped image around the stamp, and a page image containing the stamp. Metadata has a label, which is the transcription of characters on the stamp, and the proposed system uses this label as the target of retrieval. After grouping by labels and performing data cleaning, the dataset contains 5973 distinct labels. We created four experimental datasets for the minimum number of images per label. Table 1 shows that labels with more than four images cover only six percent of the dataset, and about 80% of labels have only one image. These experimental datasets are created to analyse relationships between the number of images per label and retrieval performance. Our goal was to create a program that would analyse the pictures directly without much alteration. For this reason, we kept the pre-processing to a minimum, only doing data cleaning, and focused on augmentation such as rotation and translation.
System.
We aim to develop a system that receives a cropped stamp image as a query and retrieves the most similar images from the database. In the preparation stage, we encoded all entries in the database into feature vectors using a deep learning model, specifically a VGG16 variation [2]. We used the VGG16 model, pre-trained on ImageNet, and fine-tuned on a stamp label classification task. The fine-tuning process consisted of 20 epochs of training over the dataset. After training, we removed the final layers, and the adaptive average pooling layer was used to extract feature vectors. We tested other deep- learning models, but their performance was very similar, so we chose VGG16 because it gave slightly better results. In the retrieval stage, a query image is encoded using the same model, and the similarity is computed with the cosine similarity of feature vectors between a query and entries in the database. The result is sorted in descending order of similarity, and the Top-N most similar images with distinct labels are returned.

Table 1. Four experimental datasets for the minimum number of images per label

Figure 1. Examples of cropped stamp images and their respective labels.