3. Research showcase
One key feature of the DraCor platform is the possibility to use its API (directly or through wrappers) 3 to extract structured data from the XMLs and compute textual statistics. A common procedure, for example, involves grouping texts based on metadata properties (such as period, author, or genre) and then performing comparative analyses of their network values according to the principles of literary networks analysis [10] and distant reading [8].
In this showcase experiment, run on a larger collection of texts, 4 we measured network density distribution across the best-represented genres within the corpus (tragedy, comedy, farce, historical drama). As in previous studies (Trilcke et al. 2015, Szemes and Vida 2024), we found that comic genres display a significantly higher density than tragic or historical plays (Figure 1), often because of all the characters coming together in the final scene. 5 Density also shows a moderate inverse correlation (-0.49) with network size; this is consistent with results from previous measurements on other corpora, since comic plays generally have tighter plots with fewer highly interconnected characters (i.e., high density and small network size). Since the size difference between comedies and tragedies is marginal, 6 variance in density cannot thus be explained without accounting for the specific features of comedy.
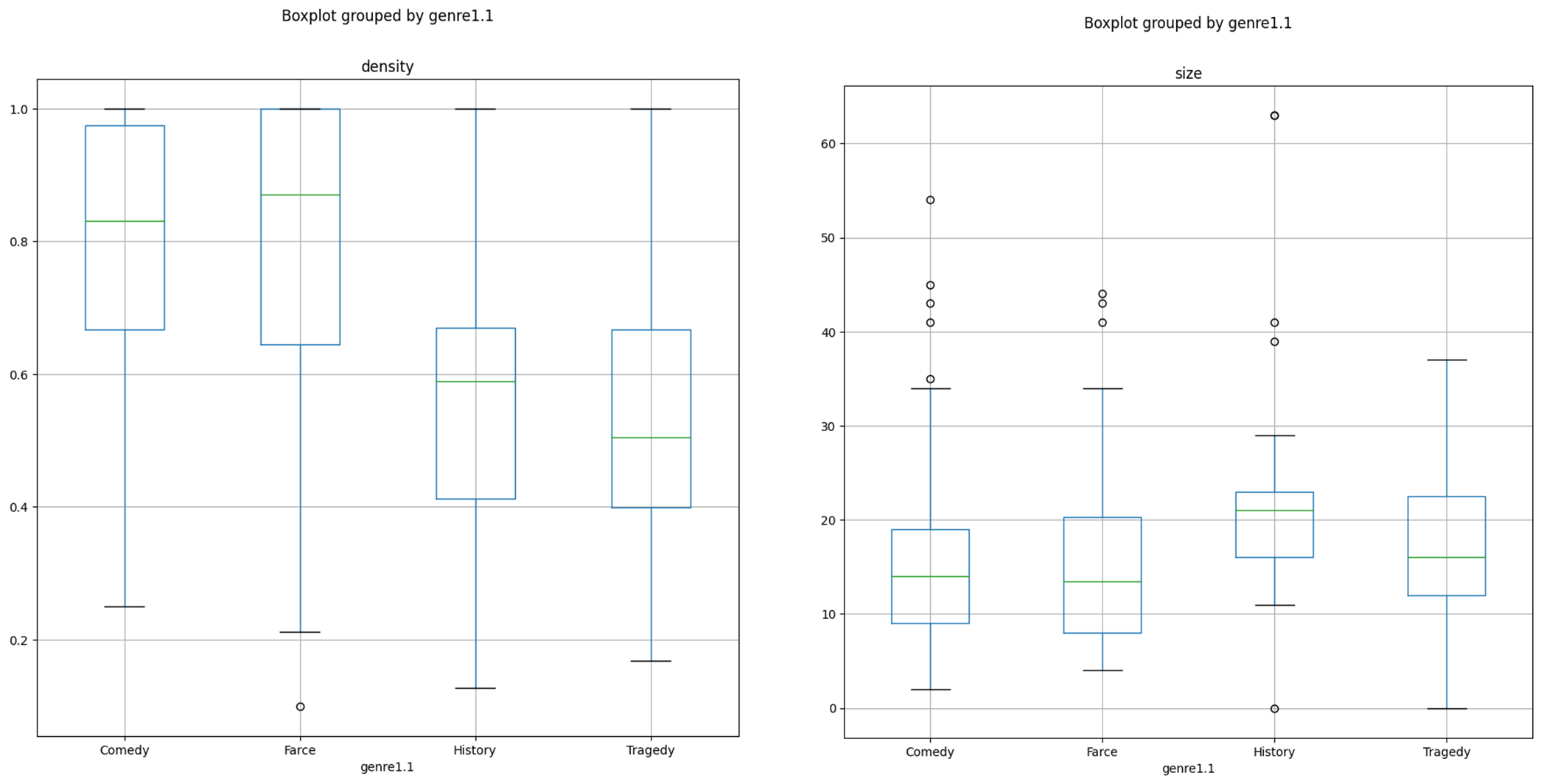
Figure 1 . Density (left) and size (right) distribution across four genres in AmDraCor .
The only genre with a notably bigger network size (median = 21) is a history play. As in some other corpora of dramatic texts, such plays often have complex polycentric networks with multiple clusters, reflecting the presentation of events spread in time and space (military campaigns, castle sieges, secret missions etc.) and depicting opposing groups of people engaged in large historical conflicts. One such example would be Jeanne d’Arc by Percy MacKaye (1907), where each act takes place at a different stage of the Hundred Years' War (Figure 2).

Figure 2. Character network for MacKaye’s Jeanne d’Arc . Data from the DraCor API, elaborated in Gephi.
While the example of exploratory data analysis we just presented is quite basic, it represents a glimpse into the potential of AmDraCor once the thorough metadata refinement and markup post-correction will be completed. In future developments, we aim at further exploiting the availability of diverse corpora in DraCor to conduct transnational analyses, as showcased in Trilcke et al. (2024). Accordingly, a possible line of inquiry could involve comparing American drama to other contemporary literary milieus, such as the French or the German dramatic texts. Even more poignantly, the ingestion into DraCor of a coeval corpus of British drama 7 into DraCor would also allow measuring whether and when US drama developed some degree of formal autonomy from its European source.