1.
Introduction
Aiming to equip young scholars in the field of Slavic medieval research with digital skills, our study has its context in developing an automated workflow to assign temporal and geographical information to Slavic medieval texts. These include handwritten and printed texts from three historical periods (10th–11th, 15th–16th, and 18th centuries), originating from South Slavic or East Slavic regions, covering a spectrum from Old Church Slavic (OCS) to its younger varieties. Some of these manually transcribed texts had served as ground truth (GT) for Handwritten Text Recognition (HTR) models (Rabus et al. 2023). On the manuscript level, they had been qualitatively attributed with temporal and geographical information (i.a. Vaillant 1974 [1930] and Krustev / Boyadjiev 2012).
In Lendvai et al. (2023) we explored domain adaptation and fine-tuning of BERT (Devlin et al. 2019) for region and time classification on the sentence level, where we uniformly used
Stanza (Qi et al. 2020) with its OCS model to segment manuscript texts. However, using this specific model might have been suboptimal since our texts have varied origins in time and space. Additionally, a sample of the sentences misclassified by BERT appeared to be syntactically and semantically less well-formed than those correctly classified. Consequently, our current study focuses on comparing sentence segmentation by
Stanza (version 1.6.1) and
UDPipe (Straka 2018, version 2.12). We focus on evaluating from a philological perspective, specifically by examining the resulting segments for well-formedness
1
, regarding a well-formed sentence as one whose boundaries do not split (i) a
clause simplex (i.e. subject-predicate structure) or (ii) complements
2
or (iii) titles. Correct sentence segmentation is a prerequisite for many tasks on such historical texts, e.g. syntactic analysis or alignment of Greek-Slavic translation. Importantly, unlike in modern languages, in OCS texts punctuation does not provide sentence segmentation guidance, e.g. bullet point-like characters are presumed breath marks and not sentence endings.
2.
Method
Both
Stanza and
UDPipe offer a model for OCS (
Stanza: language code ‘cu’;
UDPipe: old_church_slavonic-proiel-ud-2.12-230717, hereafter ‘proiel’) as well as for Old East Slavic (OES;
Stanza: language code ‘orv’, with package ‘torot’;
UDPipe: old_east_slavic-torot-ud-2.12-230717, hereafter ‘torot’)
3
.
Focusing on texts from the earliest time period (10th–11th centuries, representing South Slavic provenance), we used three manuscripts as input for the sentence segmentation task, and evaluate on the first 100 sentences in the respective GT.
1. Four texts
4
from the
Codex Suprasliensis, from the test set of the Universal Dependencies (UD) treebank. (Note that the UD treebank had served as benchmark data for training both
Stanza and
UDPipe.)
2. The translation of the
Catechetical Lectures of Saint Cyril of Jerusalem, a large part of which is preserved in an East Slavic manuscript (GIM, Sin. 478).
5
3. The translation of the treatise
On leprosy by Methodius of Olympus, as appearing in copy in a compilation from the 16th c. (GIM, Sin. 995)
6
, whereas its original is dated to the 10th c.
Note that texts (2) and (3) have no benchmark GTs, thus we created our own GT resources for them. Both (2) and (3) maintain an archaic syntax, implying that word order that is crucial for sentence segmentation resembles the South Slavic pattern typical for the oldest surviving OCS texts rather than the (more recent) OES. We assumed that their mainly graphical-orthographic changes towards the OES variety would not affect sentence segmentation. To verify this, and since OES models in principle would fit with the geographical location where (2) appeared, resp. the time when (3) appeared, we also tested the OES models on these texts. Finally, we also run the OES models on the OCS dataset (1), expecting that their performance would degrade.
7
3.
Results
3.1.
Results by Old Church Slavic models
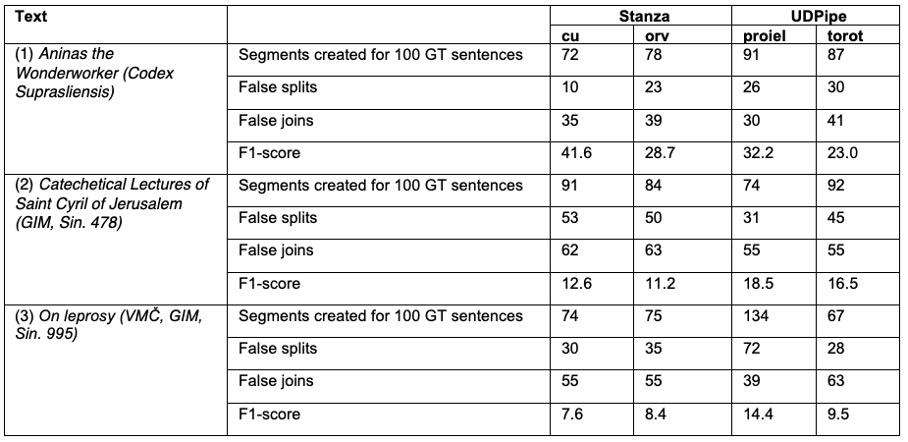
For all texts, Table 2 shows the quantification of incorrect segmentations as judged by the criterion defined in Section 1. We additionally report F1-scores calculated by the UD benchmark evaluation script.
8
The scores are low, in line with those reported on the benchmark.
9
In Table 1 we exemplify segmentation mismatches across the GT and the segmenter tools. On dataset (1), both tools’ OCS model showed similar efficacy: on
Life of Aninas the Wonderworker, Stanza generated fewer units (72) than
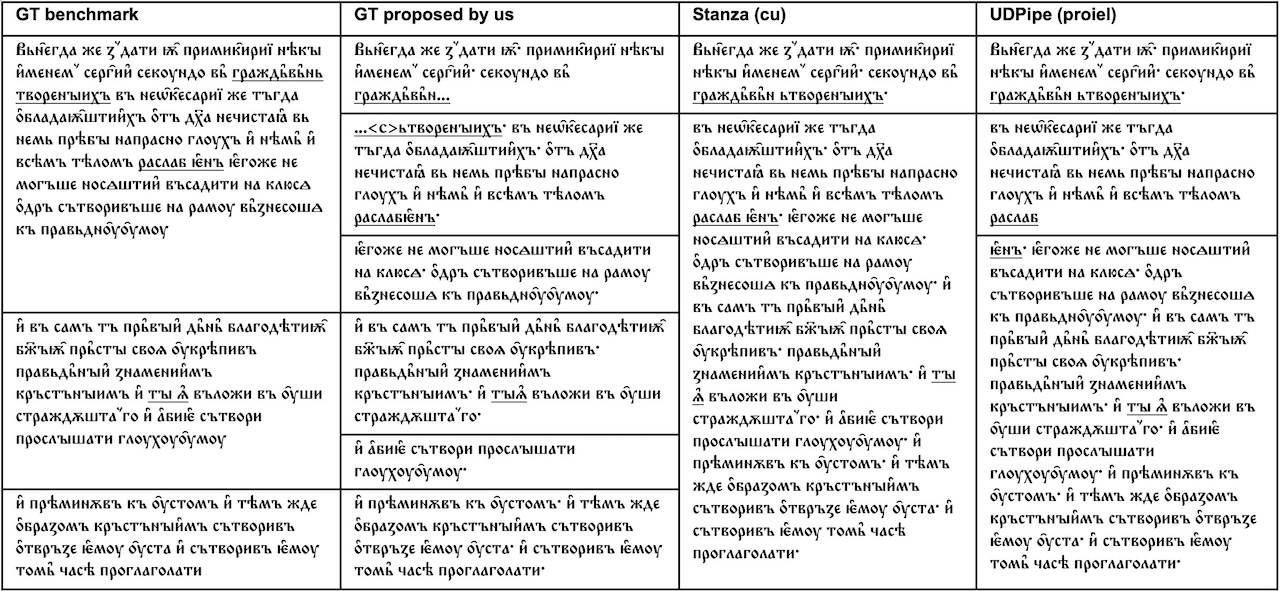
UDPipe (91). Both made incorrect segmentations (45 and 56 respectively, cf. Table 2), including shared errors due to erroneous word segmentation in the GT data leading to sentence boundaries (cf. the underlined parts in Table 1, reflecting the state of the manuscript)
10
.
Table 1:
Example of sentence boundary errors produced by OCS models on dataset (1)
On dataset (2), both tools perform considerably worse, producing similar-length yet erroneous units. Here,
Stanza created 91 units with 115 erroneous segment boundaries, while
UDPipe shows slightly better performance producing 74 units with 86 errors.
The performance disparity is most notable for dataset (3). Using the OCS models,
Stanza and
UDPipe generated 74 and 75 units, respectively.
3.2.
Results by Old East Slavic models
Applying the OES models from both tools on text (2) does not yield improved segmentation:
Stanza divides the text into 84 units with 113 segmentation errors (some due to incorrect line-end word segmentation);
UDPipe yields 100 errors in 92 created units.
For dataset (3), the OES models split the text into 134 resp. 67 units. While
UDPipe produces an even higher amount of boundary errors,
Stanza yields the least errors in this task.
3.3.
Results by Old East Slavic models on Old Church Slavic data
Running
the OES models on the OCS dataset (1), the results indicated a decline in performance as anticipated. However, the observed number of incorrect splits was not substantial; the OES models even seemed to demonstrate greater robustness against word segmentation errors.
Table 2: Quantifying segmentation in the first 100 GT sentences on dataset (1), (2) and (3)
4.
Conclusion
Our aim is to evaluate sentence segmentation, as a preprocessing step in applied end tasks such as provenance attribution of historical language data. Our current investigation indicates that both
Stanza and
UDPipe show suboptimal performance on manuscripts unseen during training, likely also because these were compiled in a language region or century different from currently available OCS and OES benchmarks. This highlights the challenges in compiling representative training resources for historical language processing.