-
Abrami, G., Bagci, M., Hammerla, L., & Mehler, A. (2022). German parliamentary corpus (gerparcor).
arXiv preprint arXiv:2204.10422.
-
Albuquerque, H. O., Costa, R., Silvestre, G., Souza, E., da Silva, N. F., Vitório, D., ... & Oliveira, A. L. (2022, March). UlyssesNER-Br: a corpus of Brazilian legislative documents for named entity recognition. In
International Conference on Computational Processing of the Portuguese Language (pp. 3-14). Cham: Springer International Publishing.
-
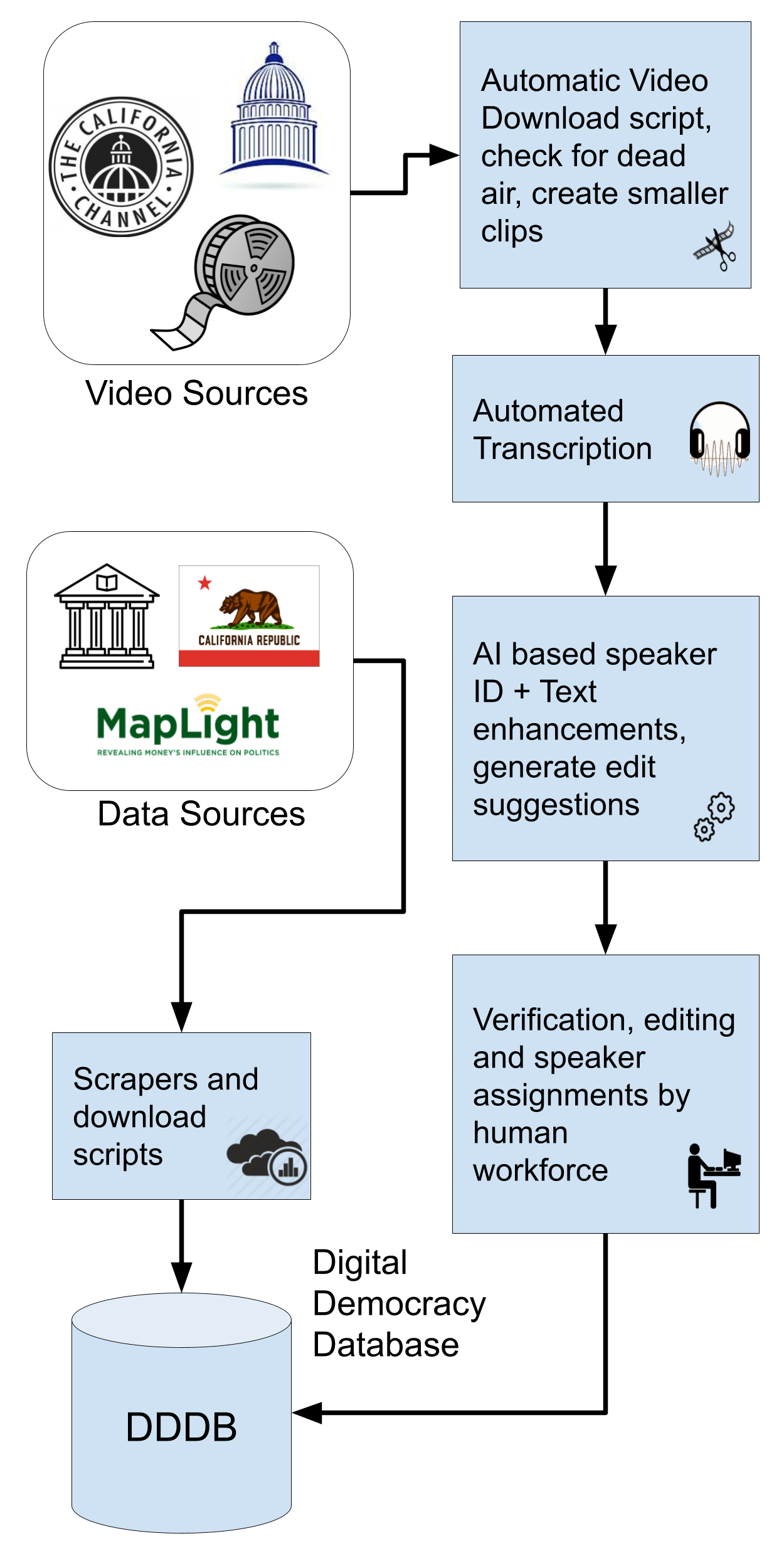
Blakeslee, S., Dekhtyar, A., Khosmood, F., Kurfess, F., Kuboi, T., Poschman, H., ... & Durst, S. (2015). Digital democracy project: making government more transparent one video at a time.
Digit. Hum.
-
Budhwar, A., Kuboi, T., Dekhtyar, A., & Khosmood, F. (2018, May). Predicting the vote using legislative speech. In
Proceedings of the 19th annual international conference on digital government research: governance in the data age (pp. 1-10).
-
CalMatters (2024) Digital Democracy. https://digitaldemocracy.calmatters.org.
-
Card, D., Chang, S., Becker, C., Mendelsohn, J., Voigt, R., Boustan, L., ... & Jurafsky, D. (2022). Computational analysis of 140 years of US political speeches reveals more positive but increasingly polarized framing of immigration. Proceedings of the National Academy of Sciences, 119(31), e2120510119.
-
Frasnelli, V., & Aprosio, A. P. (2024, May). There’s Something New about the Italian Parliament: The IPSA Corpus. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) (pp. 16037-16046).
-
Grace, J., & Khosmood, F. (2023, June 30). Feature Engineering for US State Legislative Hearings: Stance, Affiliation, Engagement and Absentees. Digital Humanities 2023. Collaboration as Opportunity (DH2023), Graz, Austria. https://doi.org/10.5281/zenodo.8108060
-
Howe, P., Robertson, C., Grace, L., & Khosmood, F. (2022). Exploring reporter-desired features for an AI-generated legislative news tip sheet. ISOJ, 12(1), 17-44.
-
Kauffman, D., Williams, M., Washington, C., Socher, G., & Khosmood, F. (2018, May). Multimodal speaker identification in legislative discourse. In Proceedings of the 19th Annual International Conference on Digital Government Research: Governance in the Data Age (pp. 1-10).
-
Külebi, B., Armentano-Oller, C., Rodríguez-Penagos, C., & Villegas, M. (2022, June). ParlamentParla: A speech corpus of catalan parliamentary sessions. In Proceedings of the Workshop ParlaCLARIN III within the 13th Language Resources and Evaluation Conference (pp. 125-130)
-
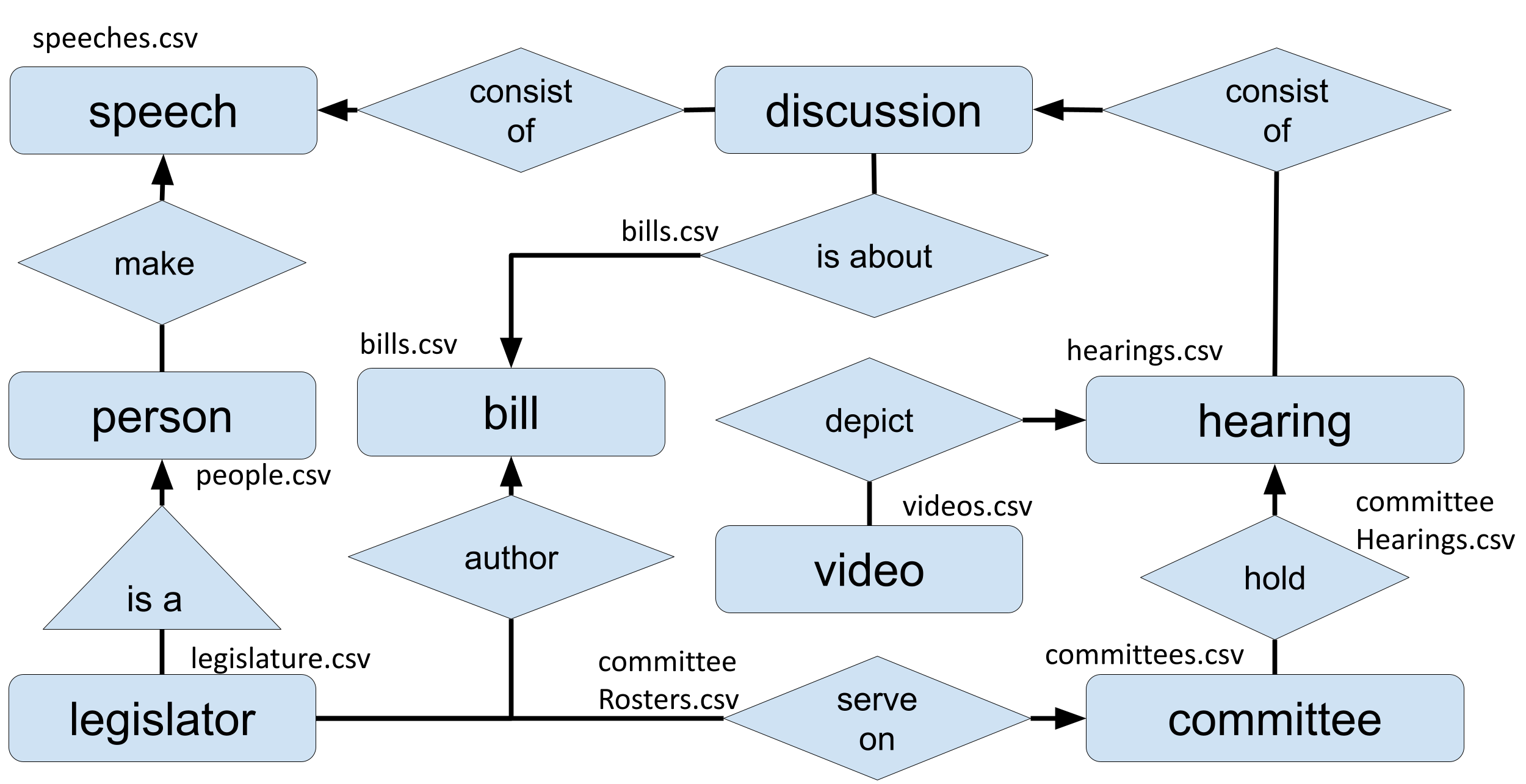
Latner, M., Dekhtyar, A. M., Khosmood, F., Angelini, N., & Voorhees, A. (2017). Measuring legislative behavior: An exploration of Digitaldemocracy.org. California Journal of Politics and Policy, 9(3).
-
Li, S. (2017). A corpus-based study of vague language in legislative texts: Strategic use of vague terms. English for Specific Purposes, 45, 98-109.
-
Maher, T. V., Seguin, C., Zhang, Y., & Davis, A. P. (2020). Social scientists’ testimony before Congress in the United States between 1946-2016, trends from a new dataset. Plos one, 15(3), e0230104.
-
Perkonigg, M., Khosmood, F., & Gütl, C. (2023, August). Automatic Bill Recommendation for Statehouse Journalists. In International Conference on Electronic Government (pp. 128-143). Cham: Springer Nature Switzerland.
-
Ruprechter, T., Khosmood, F., & Guetl, C. (2020). Deconstructing human-assisted video transcription and annotation for legislative proceedings. Digital Government: Research and Practice, 1(3), 1-24.
-
Salamanca, L., Brandenberger, L., Gasser, L., Schlosser, S., Balode, M., Jung, V., Perez-Cruz, F. & Schweitzer, F. (2024). Processing Large-Scale Archival Records: The Case of the Swiss Parliamentary Records. Swiss Political Science Review, 30, 140–153. https://doi.org/10.1111/spsr.12590
-
Tamper, M., Leal, R., Sinikallio, L., Leskinen, P., Tuominen, J., & Hyvönen, E. (2022, August). Extracting knowledge from parliamentary debates for studying political culture and language. In International Workshop on Knowledge Graph Generation From Text and the International Workshop on Modular Knowledge (pp. 70-79). CEUR-WS. org.
-
Virkkunen, A., Rouhe, A., Phan, N., & Kurimo, M. (2023). Finnish parliament ASR corpus: Analysis, benchmarks and statistics. Language Resources and Evaluation, 57(4), 1645-1670.