When analysing an unknown old text, even experts sometimes find it difficult to know when the document dates from and what kind of text it is. We propose using a document classification system to select an appropriate dictionary for this case. We show that a BERT-based document classification system could properly identify the domains of the documents and by using the appropriate dictionary for the estimated domain of the text, the performance of the morphological analysis significantly improved.
Document Classification
We propose to use a document classification system to select appropriate dictionaries for unknown old texts. We employed a BERT-based classifier [1,2]. Because BERT accepts up to 512 tokens for each input text, we extracted the initial tokens from the target document we want to know its domain to classify them.
We used the 12 Japanese corpus ranges in age, and genres vary from stories, essays, textbooks, and so on, for the following 12 UniDic dictionaries[3, 4].
They are:
1) Qkana for modern spoken / written Japanese with the old writing style,
2) Kindai-bungo for modern (1870-1945) literary Japanese,
3) Kinsei-edo for spoken Japanese in Tokyo (Edo) area in Kinsei period (1603-1869),
4) Kinsei-kamigata for spoken Japanese in Kyoto area in Kinsei period,
5) Kinsei-bungo for written Japanese in Kinsei period,
6) Chusei-kougo for spoken Japanese in Chusei period (1185-1602),
7) Chusei-bungo for written Japanese in Chusei period,
8) Waka for Japanese poems,
9) Chuko for written Japanese in the period between Jodai and Chusei (794-1184),
10) Jodai for Jodai (600-793) texts,
11) CWJ for contemporary written Japanese and,
12) CSJ for contemporary spoken Japanese.
The corpora used for the document classification system are the data used for the 12 UniDic dictionaries.
We used 3-fold cross-validation with the three datasets with minimal overlapping of the authors of the documents. The training, validation, and test data ratio is 1: 1: 1. We evaluated micro-averaged accuracy, an accuracy averaged over documents, and macro-averaged accuracy, an accuracy averaged over classes. We used class-balanced cross-entropy and normal cross-entropy for the loss function to improve the macro-averaged accuracy of document classification.
When the normal cross entropy was used, the micro- and macro-averaged accuracies were 77.80% and 57.86%, with the learning rate and epoch number being 3e-06 and 50. We also evaluated 3-best micro- and macro-averaged accuracies, which were 84.90% and 73.60%. When the class-balanced cross entropy was used, the micro- and macro-averaged accuracies were 75.50% and 59.93%, with the learning rate, epoch number, and beta being 7e-06, 50, and 0.99. The 3-best micro- and macro-accuracies were 89.80% and 81.84%.
Table 1 shows each class's 1-best and 3-best accuracies according to the loss function. We wrote the accuracies less than 50% in bold.
Table 1 Each class’s 1-best and 3-best accuracies according to the loss function
| 1-best | 1-best | 3-best | 3-best | |
| Loss function | Normal | Balanced | Normal | Balanced |
| Qkana | 68.12% | 59.81% | 72.30% | 91.72% |
| Kindai-bungo | 68.70% | 67.04% | 88.30% | 79.38% |
| Kinsei-edo | 11.11% | 26.67% | 68.80% | 84.44% |
| Kinsei-kamigata | 33.82% | 59.26% | 80.00% | 88.14% |
| Kinsei-bungo | 49.01% | 40.55% | 78.40% | 79.70% |
| Chusei-kougo | 49.18% | 69.34% | 23.50% | 53.11% |
| Chusei-bungo | 84.92% | 92.75% | 89.60% | 97.39% |
| Waka | 51.88% | 42.02% | 72.80% | 79.27% |
| Chuko | 53.35% | 44.25% | 83.80% | 81.22% |
| Jodai | 30.95% | 30.28% | 36.50% | 49.07% |
| CWJ | 95.45% | 92.41% | 88.90% | 98.79% |
| CSJ | 97.87% | 94.89% | 99.70% | 99.86% |
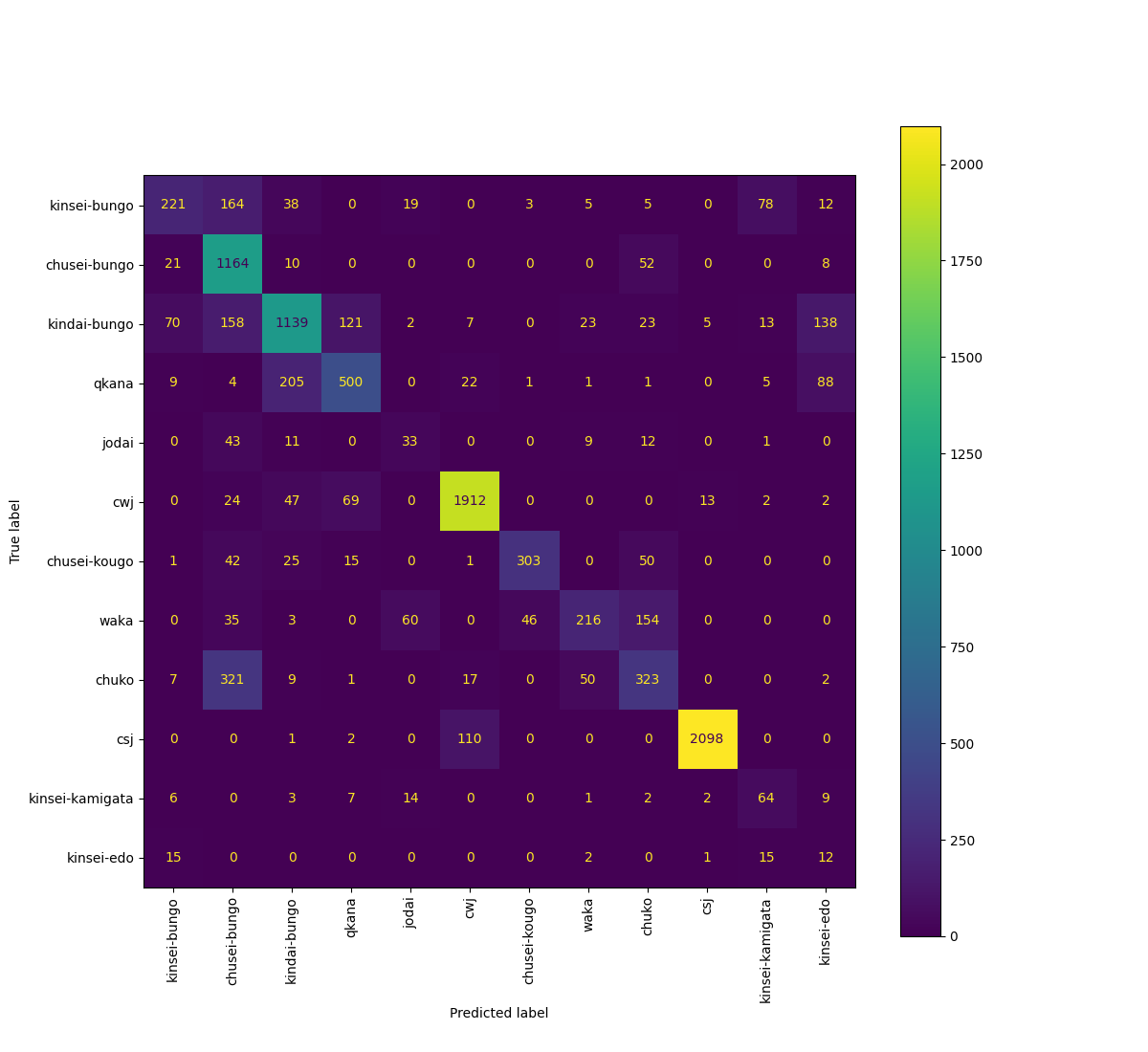
Figure 1 shows the confusion matrix of 1-best results using class-balanced cross-entropy.
Figure 1 The confusion matrix of 1-best results using class-balanced cross-entropy
According to Figure 1, the most frequent error is the confusion between Chuko and Chusei-bungo. We believe that this is because the writing style of written language in Chuko period succeed to later periods as a good example. Also, the confusion between Chuko and Waka is not crucial for analysis, because the written period is almost the same and the difference is only the registers of the texts. Likewise, Qkana and Kindai-bungo are both written languages in almost the same periods. Finally, we think that the confusion between CWJ and CSJ comes from the fact that some people sometimes write contemporary Japanese like spoken Japanese. Overall, these errors seem reasonable for Japanese experts.
Morphological Analysis
We used the document classification system to estimate the dictionary to apply the unknown texts. For evaluation, we evaluated the proposed method using MeCab [5] and the following four corpora:
1) Nihongo tokuhon 1 (URL 1) (1936-), which is a textbook written for people in Hawaii, written in modern literary Japanese for Kindai-bungo UniDic dictionary,
2) Nihongo tokuhon 2 (1936-), which is a textbook written for people in Hawaii, written in modern spoken Japanese for Qkana UniDic dictionary,
3) Part of the Amakusa edition of Qincuxu (1593), which is a reader for missionaries written in Chusei written Japanese for the Chusei-bungo dictionary, and
4) Kokin-shu tokagami (1793), which is an essay on Japanese poetry written in a mixture of spoken and written Kinsei Japanese, written by Norinaga Motoori, for the Chuko dictionary or Kinsei-kamikata dictionary.
We input the four texts into the document classification system three times because we have three models for 3-fold cross-validation. We calculated macro- and micro-averaged F-measures over these three trials. To assess the proposed method, we compared the two baselines and an oracle method:
We used Chuko and CWJ UniDic dictionaries as a baseline because Chuko texts are dominant in Japanese old text and CWJ corpus is the largest in 12 corpora.
For the evaluation of morphological analysis, we evaluated F-measures of the following four-level conditions:
Lv.1 word boundary, Lv.2 part of speech, Lv.3 lemma, and Lv.4 pronunciation.
Lv. 1 word boundary evaluation focuses on only boundaries between words. Lv. 2 evaluation assessed if the parts of speech, conjugation type and conjugation form corresponding to the UniDic word form hierarchy were correctly identified in addition to the word boundary. Lv.3 lemma evaluation checked if the lemma, pronunciation of lemma, and word class were correctly identified in addition to the evaluation of Lv. 1 and 2. Because the Japanese language has many homographs, which are words that share the same letters regardless of their pronunciations, and homophones, which are words that share the same pronunciations regardless of their letters and meanings, we evaluated if they are correctly identified. For example. “主” is a homograph that has two pronunciations, “syu” and “nushi,” and “kawasu” has more than two writings including “躱す” and “交わす.” We evaluated if they were correctly identified in this level of evaluation. Finally, Lv. 4 evaluation assessed if the pronunciations included are correctly identified including rendaku or euphonic changes.
Nihongo tokuhon 1 for Kinda-bungo was classified into Kindai-bungo, Kinsei-bungo, and Kinsei-edo classes. Nihongo tokuhon 2 for Qkana was estimated as Qkana, Kindai-bungo, and CWJ. Kinku-shu for Chusei-bungo was classified into Chusei-bungo twice and Kinsei-bungo once. Kokin-shu was categorized into Kinsei-bungo twice and Chuko once. We used Chuko UniDic dictionary for Kokin-shu. These mistakes were not crucial errors for Japanese experts like the frequent errors we discussed above.
Table 2 shows macro-averaged F-measures of Morphological Analysis according to the dictionaries. We omit the micro-averaged F-measures because of the limit of the word numbers. The bold letter means the best method of the three methods and the asterisk indicates that the proposed method outperformed the Oracle method.
Table 2 Macro-averaged F-measures of Morphological Analysis according to the dictionaries
| Macro | Levels | Nihongo tokuhon 1 | Nihongo tokuhon 2 | Kinku-shu | Kokin-shu | Avg. |
| Chuko | Lv. 1 | 86.96% | 79.05% | 92.92% | 89.86% | 87.20% |
| CWJ | Lv. 1 | 90.02% | 92.25% | 90.49% | 83.07% | 88.96% |
| Proposed | Lv. 1 | 95.80% | 96.57% | *96.06% | *92.43% | 95.21% |
| Oracle | Lv. 1 | 98.67% | 98.78% | 95.72% | 91.29% | 96.11% |
| Chuko | Lv. 2 | 81.13% | 57.66% | 85.05% | 73.57% | 74.35% |
| CWJ | Lv. 2 | 73.40% | 88.25% | 73.83% | 63.64% | 74.78% |
| Proposed | Lv. 2 | 89.93% | 91.72% | *90.41% | *77.80% | 87.47% |
| Oracle | Lv. 2 | 97.28% | 96.52% | 89.84% | 74.32% | 89.49% |
| Chuko | Lv. 3 | 79.47% | 56.21% | 84.00% | 72.44% | 73.03% |
| CWJ | Lv. 3 | 72.64% | 87.28% | 73.09% | 62.27% | 73.82% |
| Proposed | Lv. 3 | 88.98% | 91.04% | *89.79% | *76.67% | 86.62% |
| Oracle | Lv. 3 | 96.99% | 95.98% | 89.23% | 73.19% | 88.85% |
| Chuko | Lv. 4 | 75.81% | 53.22% | 82.06% | 71.48% | 70.64% |
| CWJ | Lv. 4 | 71.34% | 86.26% | 71.31% | 61.11% | 72.51% |
| Proposed | Lv. 4 | 86.83% | 90.03% | *87.99% | *75.89% | 85.18% |
| Oracle | Lv. 4 | 96.24% | 94.97% | 87.54% | 72.24% | 87.75% |
According to the tables, we can see the following three facts.
First, for all four corpora, regardless of the levels of the evaluation, the macro- and micro-averaged F-measures of the proposed method outperformed those of the two baselines.
Second, the proposed method surpassed the oracle methods for Kinku-shu and Kokin-shu. Finally, the oracle method was better when the average F-measures over corpora were compared.
Conclusion
We selected an appropriate dictionary to analyse old Japanese text using a BERT-based classifier. We showed that our system could properly identify the domains of the new example texts and by using the selected dictionary, the performance of the morphological analysis significantly improved.
Acknowledgement: This research was supported by JSPS KAKENHI Grant Number 22K12145 and the NINJAL collaborative research project “Extending the Diachronic Corpus through an Open Co-construction Environment.”
.