
1. Introduction
Movable type printing, introduced to Japan in the late 16th century from Western Europe and Korea, only flourished for approximately 50 years before yielding to woodblock printing (Takahiro 2023). Sagabon, a category of books printed with Kokatsuji (old movable type), is considered one of the most beautiful books in Japanese history. Nevertheless, the details of the printing technology, such as how the printing blocks are designed and reused, are still a mystery due to the scarcity of preserved materials. This gap in historical knowledge underscores a crucial area for research on Japanese printing technologies.
In this context, computer vision and machine learning are emerging tools for analyzing printing technologies (Guo et al. 2023, Kim et al. 2023, Kitamoto 2022) through digitized book images. Our paper contributes to this field by examining movable wooden types from old Japanese books with cursive typefaces. It addresses a challenging research question: how to identify the original printing blocks used for printing (physical objects) from book images where the boundary of each character block image (digital objects) is invisible. Although humanities scholars have performed these tasks manually (Suzuki 2006), the annotation cost was prohibitively high. To overcome this challenge, we introduce a novel two-step pipeline incorporating deep learning-based methods. The first step is to segment character block images from page images using overlapping character bounding boxes estimated through AI Kuzushiji character recognition (Kitamoto et al. 2023). This paper proposes the second step to group segmented character block images to identify original printing blocks.
2. Dataset
We used the Kokatsuji Dataset of Sagabon Tsurezuregusa (CODH 2023). It comprises 36869 character block images linked to 3966 characters. Each image has a character sequence in Unicode and the bounding box on the original page image. For hiragana characters, the jibo field gives additional information about a source kanji character of hiragana. Figure 1 shows the original page image and the bounding boxes of individual characters. While this dataset can be considered the ground truth regarding character transcription and location, it lacks information about the physical printing blocks used for printing — the missing link this paper aims to connect.
Figure 1: Page Image of Kokatsuji Dataset.
3. Method
We propose an image clustering algorithm to identify printing blocks by evaluating the visual similarity of character shapes. Identical shapes translate to the highest visual similarity. Due to the lack of ground truth, we framed this problem as a semi-supervised learning problem. Our method has two features: (1) A resilient image similarity metric grounded in contrastive learning. (2) Community detection-based clustering designed to identify printing blocks.
3.1 Similarity Metric
Structural similarity index measure (SSIM) (Wang et al. 2004) evaluates image similarity at the pixel level, thus being sensitive to subtle variations in coloring conditions. In contrast, the Siamese Network (Bromley et al. 1993) with contrastive loss can adapt to degradation in printing materials and handle missing parts, thereby being more robust in dynamic printing environments. The network uses the same weights while working in tandem on two input vectors to compute comparable output vectors. We selected Resnet18 (He et al. 2016) as the backbone, due to its deep learning architecture, the training requires a large amount of annotated data. To synergize the fixed SSIM with the adaptable Siamese Network, we applied a semi-supervised learning approach augmented by human-in-the-loop feedback.
We first initiated the Siamese Network with image pairs demonstrating high-confidence similarity scores based on SSIM. Then, to improve the network's performance, we picked up image pairs where SSIM and Siamese Network showed significant differences in similarity scores and invited experts to annotate the identicality of image pairs. Finally, we combined the SSIM and Siamese Network similarity scores to train a random forest (RF) classifier for precise character shape identification. The result shows an accuracy of approximately 97% on our human-annotated data, and this model serves as our final similarity metric in the following clustering phrase.
3.2 Clustering
We propose a community detection-based clustering algorithm for a graph representation of image similarity. The method operates on a similarity graph, with nodes representing images and edges denoting the identicality of two images. An ideal graph features edges connecting block images printed by the same printing blocks while lacking edges between block images printed by different printing blocks. To initiate the graph, we used the RF classifier to identify image pairs with high similarity to create edges. As shown in Figure 2, we sometimes observe that two subgraphs, each representing a printing block, are loosely connected within a cluster due to RF classifier errors. To separate mis-clustered images, we introduce the Louvain method for community detection (Blondel et al. 2008) to identify densely connected subgraphs, further enhancing the clustering granularity.
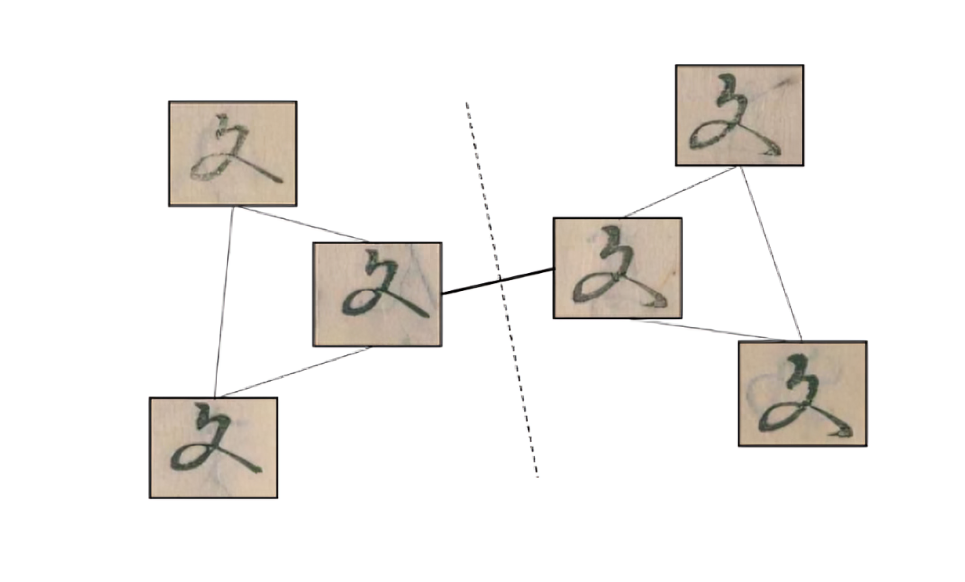
Figure 2: Community-Detection for Printing Blocks Identification
4. Experiments
We applied our method to the Kokatsuji Dataset to identify printing blocks for each character sequence of the jibo field. Our method identified 7620 distinct printing blocks from 36869 character block images.
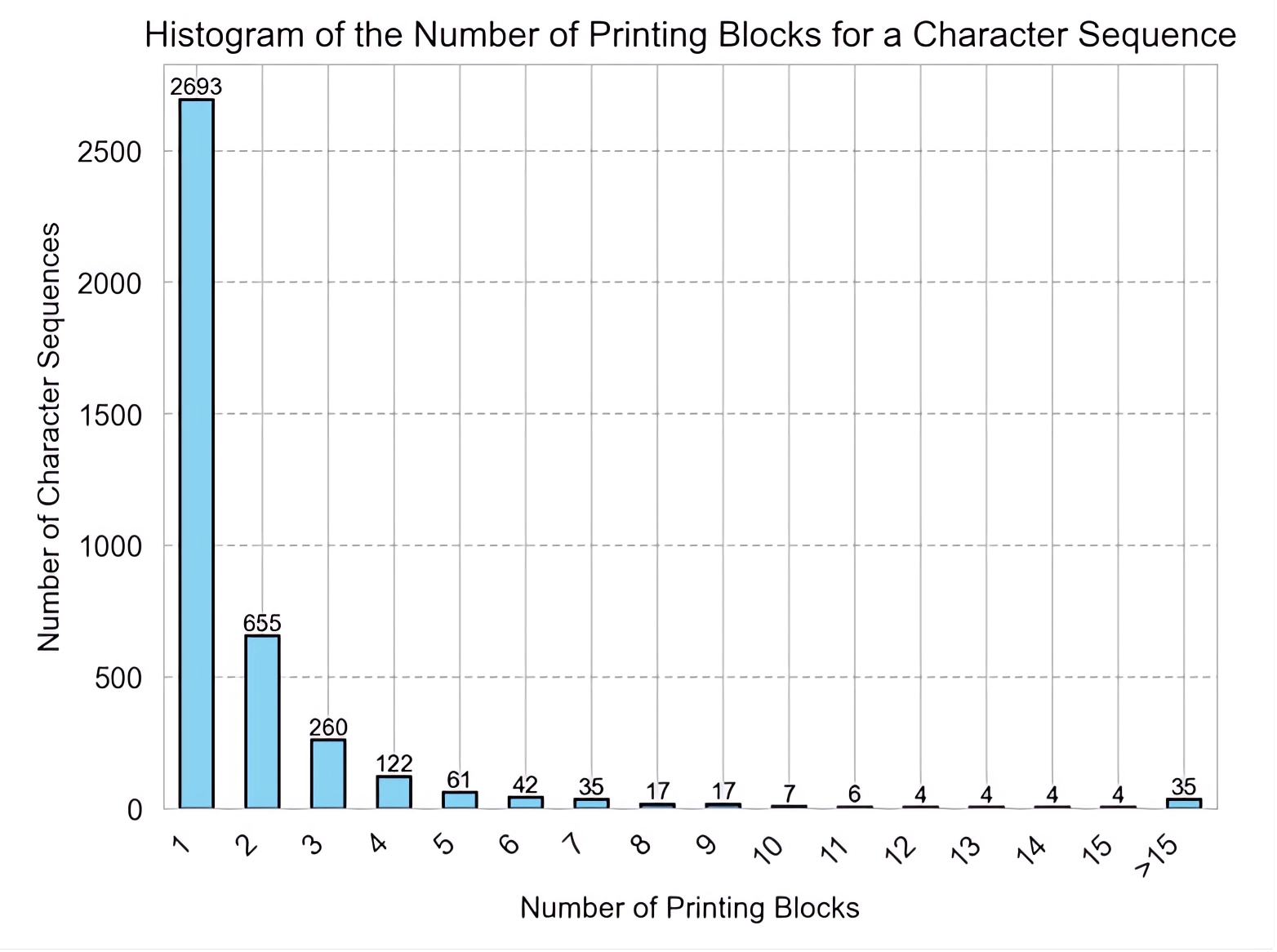
Figure 3: Histogram of the Number of Printing Blocks for a Character Sequence.
Figure 3 shows how diverse each character sequence is. The majority (90.97%) of character sequences have no more than three printing blocks, with 67.90% having only one. On the other hand, we observed 35 (0.88%) character sequences with more than 15 printing blocks, and they collectively amount to 906 (11.89%) printing blocks.
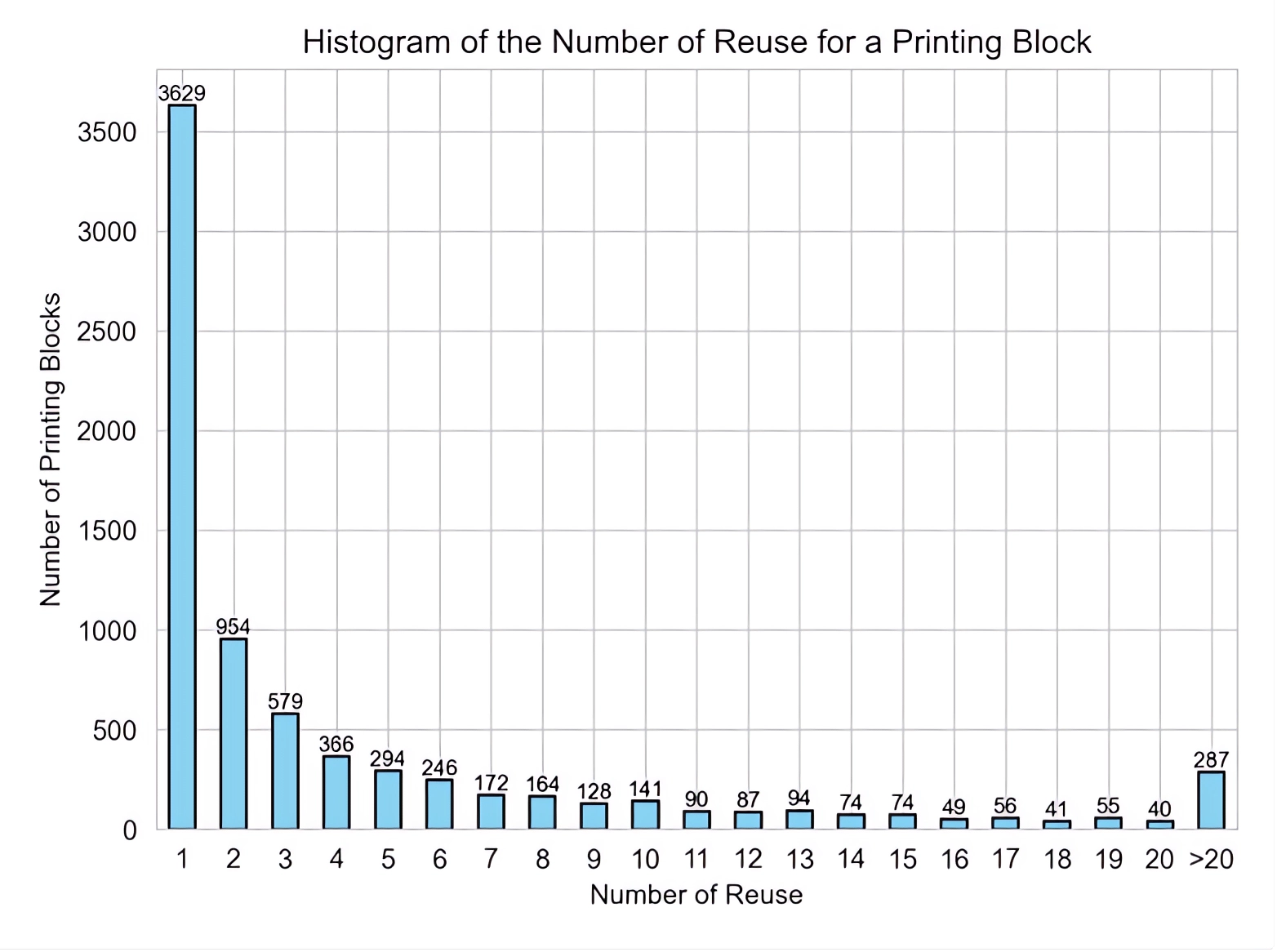
Figure 4: Histogram of the Number of Reuse for a Printing Block.
Figure 4 shows how often a printing block is reused across different pages. Approximately half (47.62%) of the printing blocks are used only once, amounting to 3629 (9.84%) character block images. There are 287 (3.76%) printing blocks that have been reused more than 20 times, and they collectively amount to 10386 (28.17%) character block images.

Figure 5: Results for a character " 文 "

Figure 6: Results for a character " 一 "

Figure 7: Results for a character " 馬 "
Figures 5-7 illustrate printing blocks identified by our method. Each column shows character block images recognized as printed by the same printing block. This result demonstrates the robustness of our method to partial ink loss but also suggests the limitation for images with excessively faded ink or simple-shape characters, such as the kanji " 一". These weaknesses indicate that our algorithm has potential for enhancement, such as bolstering the algorithm's performance for characters with minimal shape complexity with data augmentation. Due to the lack of ground truth, a quantitative evaluation of the results is unavailable, but in many scenarios, our method produces results as a good starting point for experts to refine the results.
5. Conclusion
We presented our machine learning-based approach for identifying movable type printing blocks from digitized book images. This outcome extends beyond the technical aspects: our approach assists humanities scholars in quantitative analyses of Kokatsuji books, such as calculating statistics related to the printing blocks within a single book and potentially tracking their reuse across different books.
6. Acknowledgment
The authors thank the National Institute of Japanese Literature and the Sogo Shomotsugaku Project for providing us with the data, advice, and expert annotations. Also, we thank CDH (EPFL) for their generous support in funding the travel associated with this research.