1.
Introduction
The digitization of humanities resources is progressing rapidly, and with it, the availability of full-text databases containing classical books and old documents. However, the incorporation of non-registered Chinese characters, known as "gaiji", within these databases presents a unique set of challenges. One common issue is the dependence on specialized software for the registration or editing of character glyphs, making effective management a complex task. To address this, the article introduces hi-glyph, a web application aimed at providing an alternative solution to existing challenges associated with character management in digitized humanities databases.
2.
Related Research
The Unicode standard, housing over 97,000 Chinese characters for computer use, faces hurdles in accurately reproducing original fonts in databases containing ancient documents and classical texts (The Unicode Consortium 2022). This challenge is met with the utilization of glyph images for unregistered characters in Unicode, as exemplified by the "Integrated Database of Hanzi Dictionaries in Early Japan (HDIC)" (李 et al. 2020) (劉 et al. 2020) (池田 et al. 2022). GlyphWiki
1
(Kamichi 2004) serves as a platform for registering these glyphs, but its limitations become apparent for long-term institutional use. The article underscores the need for a more robust and open-source solution, leading to the development of hi-glyph.
3.
Design of the Character Glyph Management System
To address the challenges posed by GlyphWiki, hi-glyph is meticulously designed to meet three core requirements. Firstly, the system's source code is open and released under an open-source software license, ensuring its operability by institutions or user-owned servers. Secondly, a user management system is introduced to regulate character glyph use and management, adhering to strict permissions for registration, editing, deletion, and controlling the public exposure of characters. Lastly, data management functionalities are developed to collectively add, delete, and back up multiple character glyphs. The design prioritizes user-friendliness, open-source compatibility, and institutional viability.
4.
Implementation and Application of hi-glyph
The hi-glyph is implemented as a web application using JavaScript (TypeScript). The deployment occurs on a Node.js environment server. The glyph data is stored in KAGE data, which records the skeleton information of Chinese character strokes. Open-source software libraries are leveraged for character image generation and editing. The system's source code is planned for public release on GitHub under the MIT License
2
, ensuring its redistributability. The comparison between GlyphWiki and hi-glyph reveals the latter's enhanced features, including a more structured character data table, permission management via role-based access control, and functionalities such as setting disclosure ranges for individual characters (Figure 1).
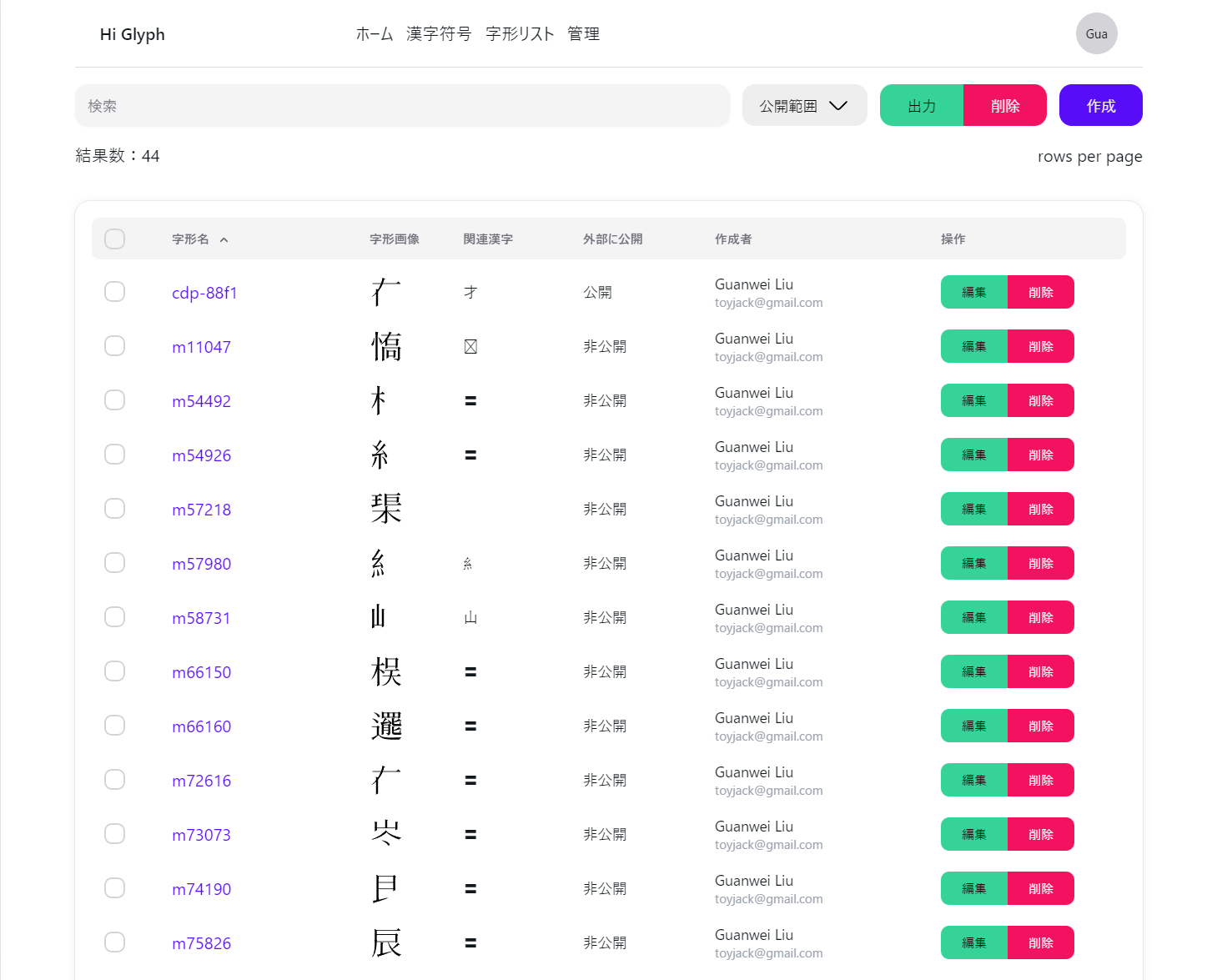 Figure 1: Glyph data management interface
Figure 1: Glyph data management interface
In a practical demonstration of hi-glyph's capabilities, the article discusses its application in the text databases provided by the Historiographical Institute at the University of Tokyo. Those databases utilize a 16x16 pixel bitmap glyph of the GT Shotai font (東京大学多国語処理研究会 2021) to display gaiji characters from the time of its construction. We applied hi-glyph to the “Nara Period Old Documents Full-Text Database”, specifically one of the databases. Despite most characters being encoded due to Unicode updates, 13 characters remain unencoded (Figure 2). Through hi-glyph, higher-resolution gaiji character glyph images are created, showcasing the system's effectiveness in addressing specific challenges within the context of historical document databases (Figure 3).
 Figure 2: List of glyphs created for the “Nara Period Old Documents Full-Text Database”
Figure 2: List of glyphs created for the “Nara Period Old Documents Full-Text Database”
 Figure3: Comparison with GT Font glyph image
Figure3: Comparison with GT Font glyph image
5.
Conclusion
In conclusion, the article provides a comprehensive overview of the development and application of hi-glyph, positioning it as a robust solution for the efficient and secure management of Chinese character glyphs in digitized humanities databases. The system's user-friendly interface, open-source nature, and successful application in addressing specific challenges exemplify its potential significance in the realm of humanities digitization. The authors hint at future discussions, promising a deeper exploration of hi-glyph's prospects and detailed applications. As hi-glyph emerges as a promising advancement, it offers a tangible solution to the intricate challenges associated with gaiji character management, contributing significantly to the evolving landscape of digitized humanities resources.