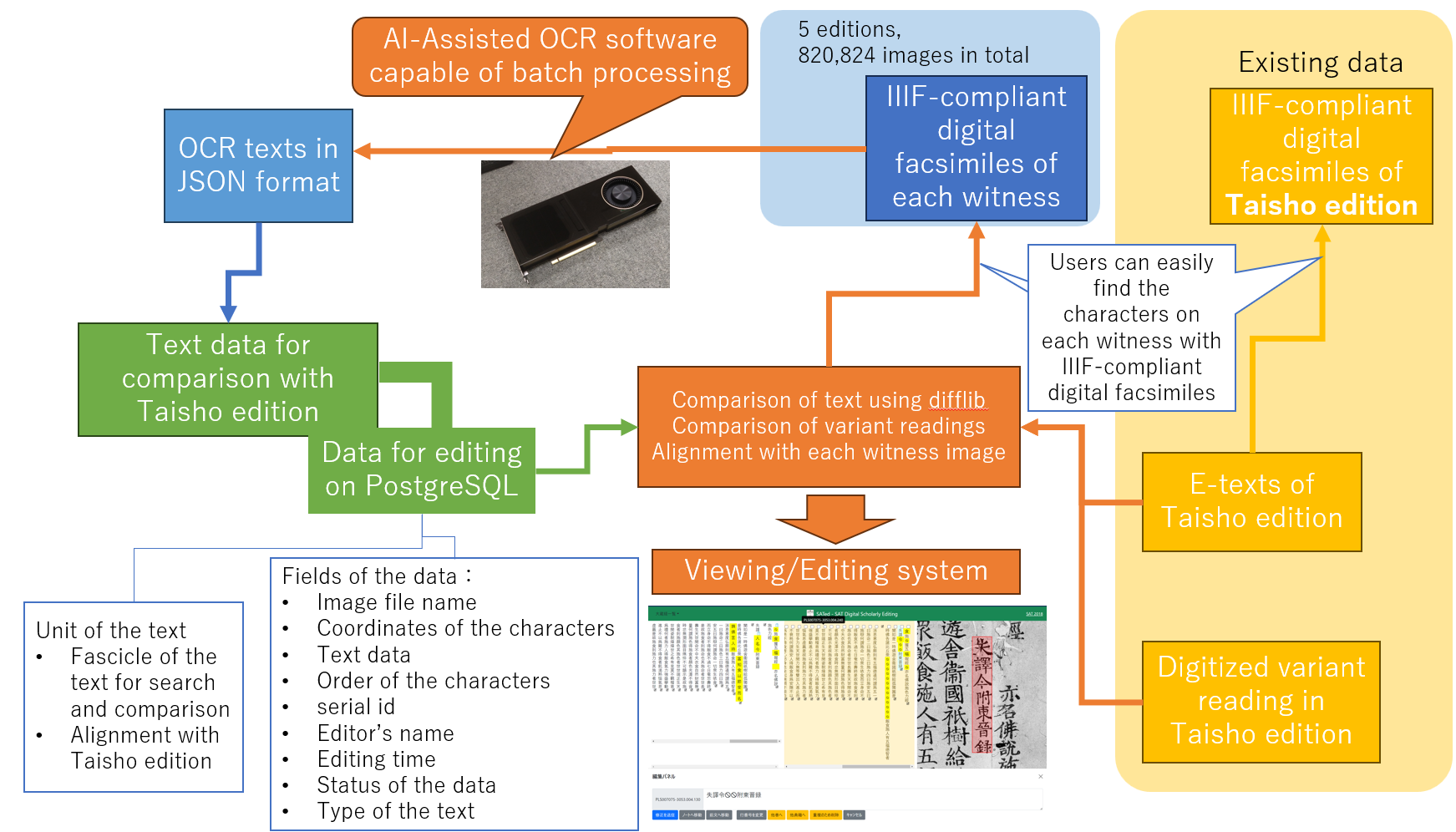
Figure 1. The structure of SATed
The construction of digital scholarly editions is an essential endeavor for appropriately advancing humanities in the digital age, and extensive research has been conducted from various angles, focusing mainly on Latin script texts[1]. However, non-Latin script literature faces challenges, as they often lack sufficient representation in Unicode, making OCR (Optical Character Recognition) and HTR (Handwritten Text Recognition) inherently difficult. This has led to difficulties in developing digital scholarly editions for non-Latin scripts compared to their Latin counterparts, resulting in less widespread adoption. This study aims to improve this situation by presenting useful methods for constructing scholarly editions with non-Latin script literature.
The authors are working on a digital scholarly edition based on the Taisho Shinshu Daizōkyō (Taisho edition), a collection of Buddhist scriptures[2]. This text, printed in typescript from 1924 to 1934, has been digitized and consists of over 100 million characters, mainly in Chinese and Japanese. The authors' project has registered over 3,000 characters in Unicode (ISO/IEC 10646) but still contains several hundred unencoded characters, and efforts for their encoding continue[3]. The project involved over 200 researchers who proofread this extensive text twice, resulting in a highly accurate text database published in 2008. The database has been continually improved, including features that allow comparison of digital images of witnesses, available on cultural institutions' websites worldwide, on their site using the IIIF (International Image Interoperability Framework) standard. However, the alignment is not perfect and is based on 'volumes,' making it inefficient for users to search for corresponding sections in texts and images, which can be up to 30,000 characters long, and requires checking each character individually. The solution presented significantly improves this situation and has the potential to transform the behavior patterns of users of this digital scholarly edition, particularly researchers of Buddhist scriptures.
The solution, SATed (SAT Digital Scholarly Editing System), primarily utilizes manually created text data and highly accurate AI-assisted OCR/HTR software developed by the National Diet Library in Japan[4]. It currently targets five woodblock editions, totaling 820,824 images. The OCR software used in SATed achieves an accuracy of over 92% for these woodblock editions. Its availability as open-source software made batch processing feasible, enabling the realization of this system. SATed compares the high-accuracy OCR text, line by line, with the Taisho edition text using Python's difflib library. Differences are identified, and users can verify these on a browser by clicking on the text, seeing the differences between the Taisho edition, OCR text, and corresponding image location information. Additionally, users can correct OCR errors in the browser, though currently, this requires Google login due to technical limitations. (Figure 1, Figure 2)
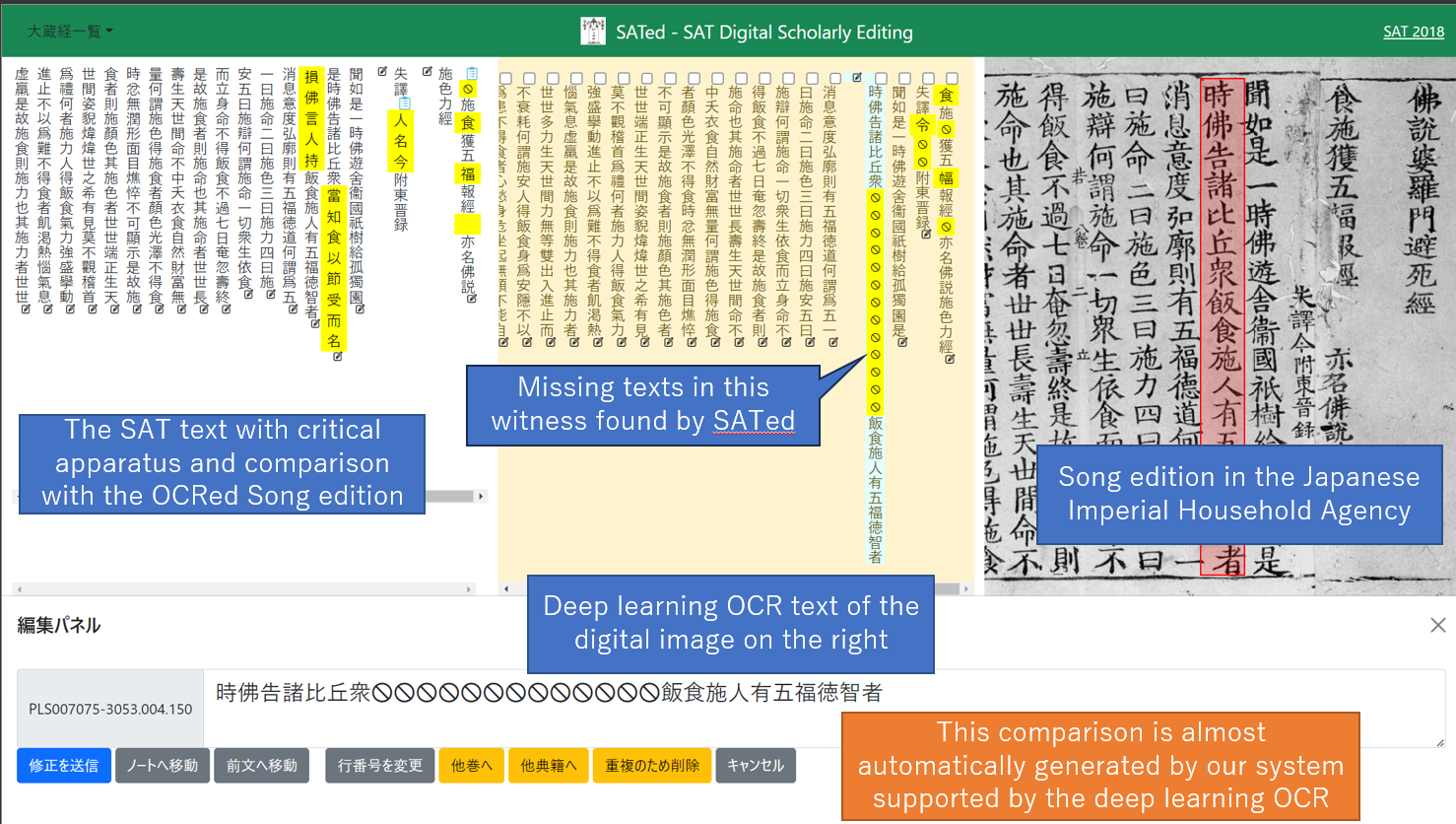
This system greatly improves the efficiency of verifying variant readings in the Taisho edition. Previously, every character had to be checked manually, but now, the system identifies areas that require comparison, significantly reducing manual effort. It also offers a system for correcting OCR text, allowing for more accurate verification. Currently, the system requires batch processing but can be expanded to include new witnesses. This capability frees researchers from the laborious task of checking every character against digital facsimiles, potentially increasing participation in social editing[5] and broadening the possibilities for the development of scholarly editions.
This mechanism is not only applicable to Buddhist scriptures but also to East Asian literature in general, and its widespread adoption is anticipated. Although directly using this system may be challenging, it demonstrates the potential to provide efficient digital scholarly editions for non-Latin script texts by properly registering necessary characters in Unicode and training AI-OCR software.