1.
Abstract
We present a modular software pipeline for interpretable stylometric analysis. It connects modern text preprocessing and extraction of linguistic features with various NLP tools, a state-of-the-art classifier, an explainability module, and finally visualisation that shows general and detailed explanations of what linguistic features make texts differ.
2.
Aim
Performing text classification in itself is a solution to only some problems (like authorial classification, e.g., in forensics). It is not sufficient in cases when an actual description of characteristic stylistic features is desired. Our main aim is to extend the classification capabilities of existing software for stylometric analysis (Eder et al. 2016) with better explainability/interpretability Molnar of features that distinguish between text styles. One way to obtain such interpretability is to first train a machine-learning model – in our case, a classifier distinguishing between two or more types of texts – sufficiently well so that one can assume that the model has encoded useful information about the texts, and afterwards, to extract information on what features and to what extent had been responsible for that model’s decisions.
3.
System features
Despite the overwhelming success of transformer-based neural networks in language processing, making them interpretable poses an enormous challenge. Hence, we decided to use (i) tree models, which are easily interpretable and for which the explanations can be computed fast Lundberg et al. (2020), (ii) feature engineering approach, where the features are rooted in linguistic knowledge. Specifically, the features which we made available to the classifier are the frequencies of:
– words (and their n-grams)
– lemmas (and their n-grams)
– punctuation
– named entities and entity types
– dependencies (i.e., dependency-based n-grams as well as dependency relations)
– parts of speech (and their n-grams)
– morphological annotations (and their n-grams)
see also Fig. 1. We also allow culling, i.e., ignoring tokens that have document frequency strictly higher or lower than the given threshold.
4.
System design
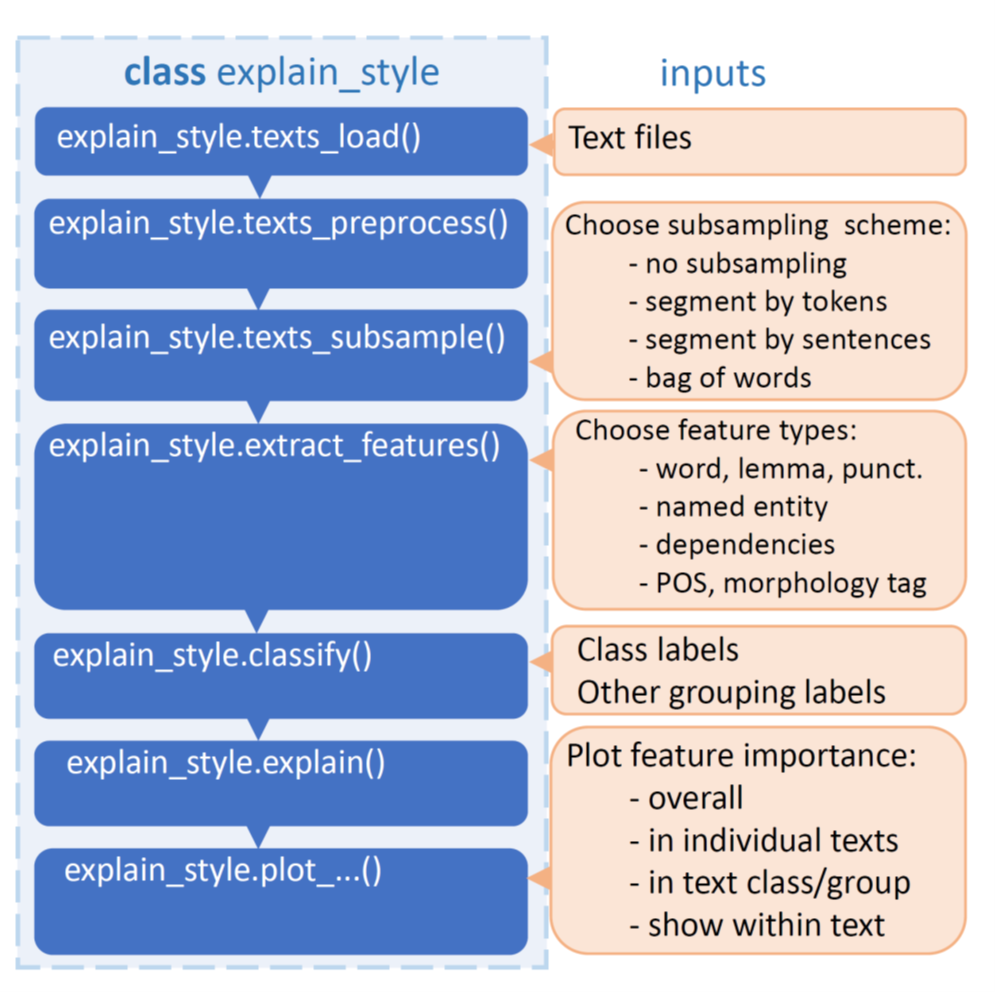
The general design is a Python package with modules responsible for loading a text corpus, preprocessing the texts, optional text subsampling into segments, feature extraction, classification, explanation and visualisation, as illustrated in Fig. 1. All these modules are wrapped as methods of one class explain_style. A user can run all of them manually or let them run automatically until explain_style.explain(), after which the user decides what information they would like to visualise. Retaining the manual control over each step allows the user to skip already precomputed processing stages by loading:
– already preprocessed texts
– precomputed features
– a trained model
– precomputed model explanations
and introduce modifications to some parameters and run the rest of the pipeline. There are several sets of parameters that can be modified, regarding:
– preprocessing
– the classifier
– cross-validation
– text subsampling
–
the choice of the feature set.
In most cases, the last parameter set would be the most interesting to change
during a stylometric analysis.
At present, we use Spacy (Montani et al. 2023) for preprocessing steps (in-
cluding tokenisation, named entity recognition, dependency parsing, part-of-
speech and morphology annotation), LighGBM (Ke et al. 2017) as the state-
of-the-art boosted trees classifier, SHAP (Lundberg et al. 2020) for computing
explanations, and Scikit-learn (Pedregosa et al. 2011) for feature counting and
cross-validation.
Fig. 1 The general overview of software modules.
5.
Example of usage
We have been testing our pipeline mainly on Polish texts, both on collections
containing several genres and authors, and on pairs of single texts. Below, in
Fig. 2-3, we show some of the results of comparing two translations of Joseph
Conrad’s "Heart of Darkness" – by Aniela Zagórska and by Jacek Dukaj. Single
novels involve the abovementioned subsampling (classifying several smaller text
segments), where sample length is a hyperparameter, here set to 800 tokens.
Features used: lemma 1-3-grams, dependency-based lemma bigrams, POS-tag
1-3-grams (including punctuation), unigrams of morphological tags (including
punctuation), named entity types, and named entities. The classifier results
reached
accuracy = 96%,
F1 = 0.96,
Matthews correlation coefficient = 0.92,
averaged over 10 repetitions of 10-fold cross-validation.
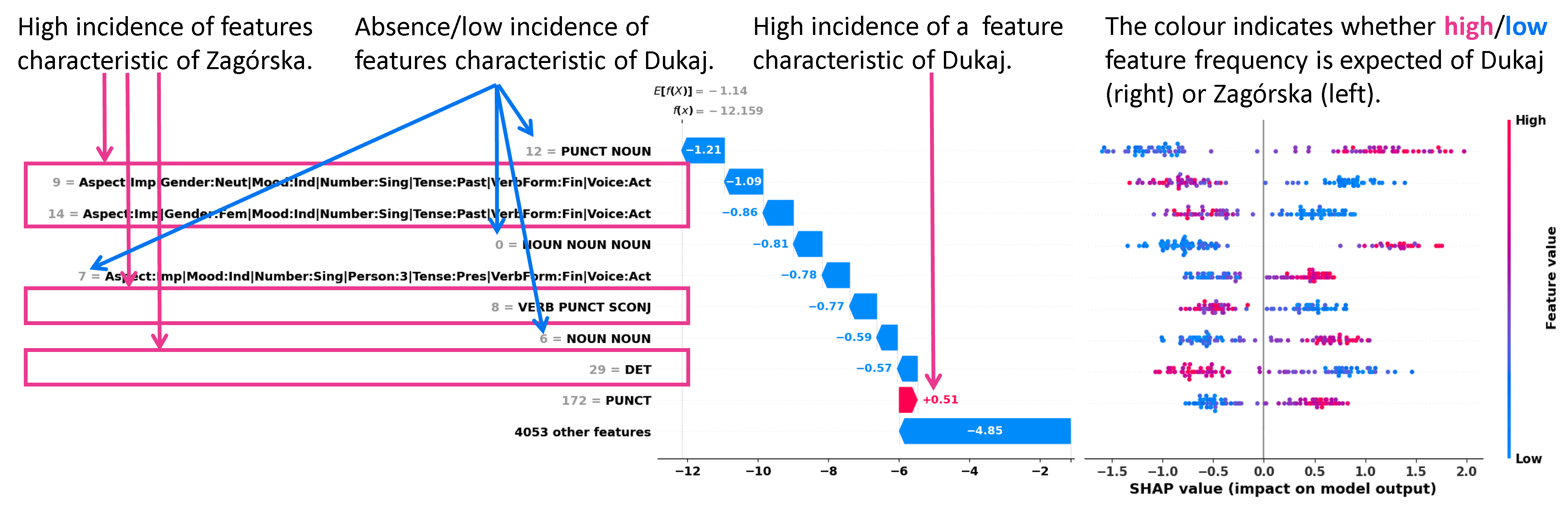
Fig. 2 SHAP explanations for binary classification into Dukaj or Zagórska. Left: Names of the nine most important features and their incidence in the segment 49/50 of Zagórska's translation.
Middle: SHAP values explaining the decision for that individual segment (classified correctly).
Right: SHAP values for all text segments – one dot representing one segment. Positive values point to Dukaj, and negative to Zagórska.
Fig. 3 Interlinear SHAP explanations in a text fragment from Zagórska's translation. Colour boxes indicate features found important for classification. For n-grams, the boxes are followed by colour lines. A positive number within the box points to Dukaj, and a negative to Zagórska.
6.
Outlook
The pipeline modules can be substituted with other choices, especially of the classifier or one or more of the preprocessing tools. The list of available features can be extended depending on the availability of such tools for a given language (e.g., sentiment, metaphors or direct/indirect speech).
7.
Acknowledgments
Research financed by the European Regional Development Fund as a part of the 2014–2020 Smart Growth Operational Programme, CLARIN—Common Language Resources and Technology Infrastructure, project no. POIR.04.02.00-00C002/19. This venture has been made possible thanks to the funding provided by the Jagiellonian University’s Flagship Project “Digital Humanities Lab”.