1.
Introduction
In the late medieval and early modern period, there was a notable surge in the documentation of property ownership, sales, and rents. In the context of the city of Basel, these records were compiled in the early 20th century into the Historical Land Register
1
, comprising source excerpts closely aligned with the original texts. Our research focus is on 80,000 documents dating from 1400 to 1700.
2
The magnitude of this archival compilation poses challenges for research inquiries and suggests that there is value in a machine-learning approach to extracting relevant information from the documents.
A first step for other information extraction methods, such as extracting events, is often the annotation of entities (Li et al. 2024). In previous experiments, I investigated the possibility of detecting named entities in the historical tower books of Bern (Hodel et al. 2023). An additional challenge arises from the documents within the historical land records: over 30% of all entity mentions therein are nested within other mentions (see Table 1 for an example). Nested Named Entity Recognition (NNER) is a well-known challenge in Natural Language Processing (Wang et al. 2022), although it receives much less attention than so-called “flat” Named Entity Recognition. For our purpose, standard NER recognition is not sufficient, as we would miss relations and events which are embedded within entity mentions. In this proposal, I report the findings of my experiments applying an established NNER architecture to the Historical Land Records of Basel compared to a method I developed.
2.
Methodology
The documents were automatically transcribed using Handwritten Text Recognition with an average error rate of 3.6%. We annotated 828 excerpts with the BeNASch-system (Prada Ziegler et al. 2024), an annotation framework developed for pre-modern German texts,
which is inspired by the ACE2005 guidelines. ACE
3
is a common benchmark for NNER in modern English (Wang et al. 2022).
While our annotations are more nuanced, this paper focuses on the evaluation of entity boundary detection and entity type classification. Targets are entity mentions of the types
person (PER),
organization (ORG),
location (LOC) and
geopolitical entities (GPE).
To get a vectorized representation of the strings, I trained a character-based language model with the Python NLP framework
Flair (Akbib et al. 2018; Akbib et al. 2019), fine-tuning a general modern German model provided by the Flair framework, using slightly preprocessed texts from the Historical Land Records. Flairs contextual character embeddings have previously proven to perform especially well with pre-modern German language (Hodel et al. 2023).
The initial approach I tested for the recognition task uses a classic BiLSTM architecture with a modified CRF layer to detect nested annotations using a
second-best decoding strategy developed by Shibuya and Hovy (2020). I chose this architecture because an implementation using Flair language models was publicly available and it scored state-of-the-art results compared to similar systems (Wang et al. 2022).
The second method, developed by myself, is a simple recursion strategy using a typical Flair model trained to annotate flat NER tags. This model is trained on modified training data, where each annotated span in a document is represented as a sample in the training data (see Table 1).
4
On inference, the system starts annotation on the document level. Whenever an entity mention is found, the span of that mention is annotated until no further annotations are found. This paper will refer to this method as “recursive system” from this point forward.
5
3.
Results
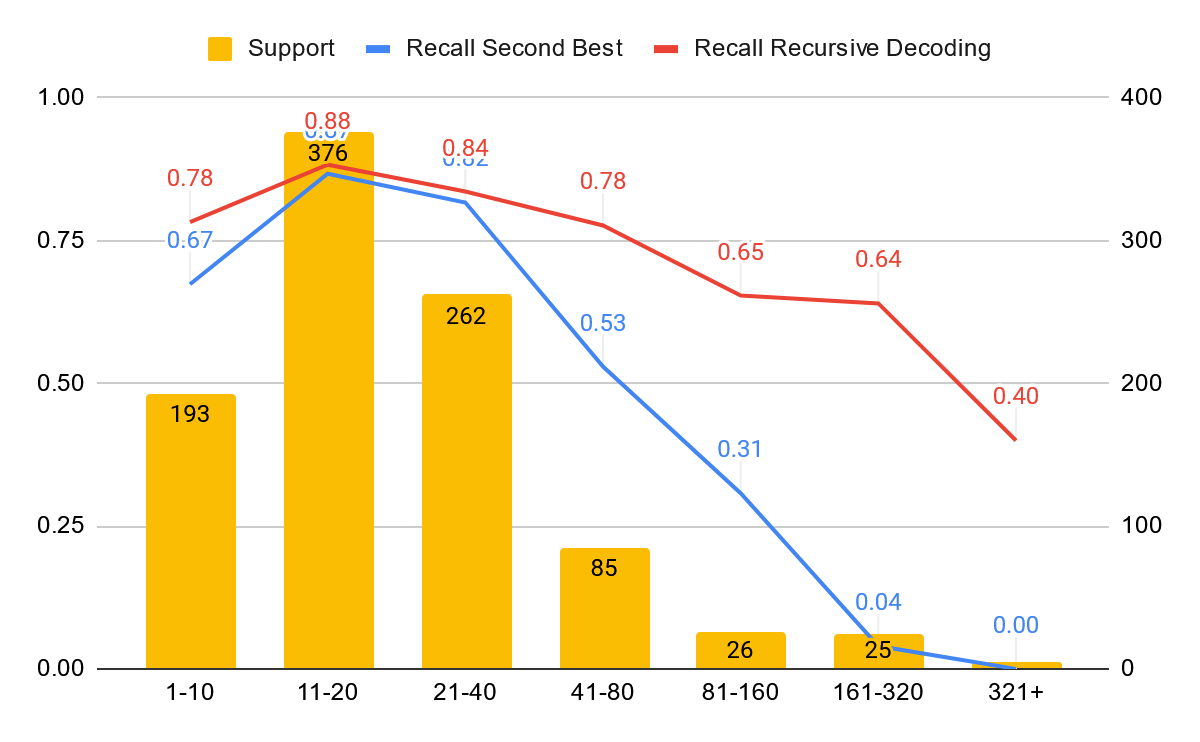
The results of the experiments are shown in Table 2. The recursive system performs better by each metric in each category, except for geopolitical entities. Investigating the strongest indicators for failing to detect a sample, only one factor is showing a strong significance in all categories: Annotation length. In Figure 3, the recall is compared between both systems in respect to annotation length. While both system tend to perform worse with longer spans, the recursive system performance manages recognition of long annotations significantly better.
It is difficult to put the resulting numbers of the recursive system into context due to the lack of comparable experiments. Compared to the flat annotation experiments with the tower books of Bern based on similar material (Hodel et al. 2023) these numbers look exceptionally well, especially considering the increased difficulty of the task itself. In practical terms, we can confirm that a model trained with this method to recommend annotations already considerably speeds up our annotation process by pre-tagging documents.
4.
Conclusion
Nested entities in pre-modern German-language land records can be detected reliably. While it comes as a surprise that a state-of-the-art architecture performs worse than a simple recursive application using a traditional NER model with some modified training material, this can probably be attributed to the special setting of the experiment: For one, appr. 50’000 tokens training material is an extremely small corpus to train on, and second, the architecture by Shibuya and Hovy is usually used with richer embeddings than just Flair, such as BERT embeddings and stacking them.
Finally, I would attribute the scores achieved in this experiment to a large part to the domain of the utilized texts. The documents collected in the land records often follow a strict structure. Such repeating patterns are easily picked up by machine learning systems. Furthermore, the frequent repetition of names due the identical geographical origin of the registers is supportive. How well a model like this can generalize to other domains or land registers from other cities is subject to further research.
These findings lay the groundwork to perform further information extraction tasks on historical mass data. Reliable detection of named entities will be important to the tasks of relationship and event extraction in particular.