1.
1. Introduction
Writing commentaries about great literary works is a scholarly practice that arose alongside the works themselves, from the Talmudic teachings on the Torah to the Alexandrian reception of Homer’s epics. Commentators’ glosses present the reader with any information deemed important for reading and understanding the text. As such, they tend to span a wide variety of domains (e.g., mythology, history, language, textual tradition) and point to relevant primary and secondary literature on a given passage.
In the field of Classics, not only has the tradition of commentary writing been particularly prolific, but scholars have been carrying out in recent years a methodological reflection on the limitations of the commentary genre, as well as on the potential of the digital medium to transform both the past and the future of commentaries (Most 1999; Gibson and Kraus 2002; Kraus and Stray 2016). As Heslin rightly noted (2016), digitised commentaries have been of very limited usage to researchers, despite their high potential usefulness (e.g., enabling easy, direct access to older commentaries). Key limitations that hinder their usage include inaccurate metadata, a lack of indexes to access their contents, and the mediocre quality of OCR transcription (particularly for Polytonic Greek).
In this paper, we present the Ajax Multi-Commentary (AjMC), a new platform that provides access to modern commentaries on Sophocles’
Ajax and leverages the digital medium to ease and speed up the work of comparing commentary glosses.
1
The creation of this platform was enabled by a processing pipeline which makes our approach adaptable to other commentaries. We start the paper by briefly describing this pipeline (Section 2) and continue by presenting the main functionalities of the Multi-Commentary platform (Section 3).
2.
2. Processing Pipeline
Our pipeline
2
processes a corpus of 17 digitised commentaries on Sophocles'
Ajax, published between 1835 and 2011 in German, English, French, Italian, and Latin.
3
It starts by converting digitised pages into textual data using optical character recognition (OCR). Although state-of-the-art OCR models excel with clean monolingual documents, their performance tends to degrade with historical, multilingual or multi-script materials (Romanello, Najem-Meyer, and Robertson 2021). Thanks to specially designed attention models, we are able to exceed the accuracy thresholds recommended for further textual analyses by Hill and Hengchen (2019) and van Strien et al. (2020).
We then use document layout analysis (DLA) to segment OCRed pages into text regions such as source texts, glosses, and critical apparatus. To achieve this, we compared state-of-the-art models using text (RoBERTa), image (YOLOv5) and both features (LayoutLMv3) (Najem-Meyer and Romanello 2022). Our experiments show a clear advantage in favour of YOLO, even though the model struggles to generalise to unseen layout types. Though not suitable for production yet, this approach already supports semi-automatic procedures by accelerating manual annotation.
The third step of the pipeline aims to enrich the segmented glosses by recognising and disambiguating the entities they contain (authors, works, mythological characters, etc.). The availability of AjMC’s data in HIPE 2022 (Ehrmann et al. 2022; Romanello and Najem-Meyer 2024) enabled us to assess the difficulty of both tasks. Recognition involves detecting and classifying entities and shows very promising results, with a fine-tuned multilingual historical BERT (Schweter et al. 2022) achieving F-scores of 91.3%, 84.2%, and 85.4% on German, French, and English glosses respectively. Disambiguation then involves linking the extracted entities to their corresponding Wikidata entries. These results are less encouraging, as the ubiquitous use of abbreviations poses a significant challenge. Only 1.4% of correctly predicted entries come from abbreviated entities, despite them constituting 47% of the testset.
The final step of our pipeline aims to align all the glosses on a given passage, which is determined by the gloss’s textual anchor. These anchors are often composed of both line numbers and Greek characters and concentrate a large number of transcription errors, which makes the task highly challenging. This is the only step in the pipeline that is currently executed manually.
3.
3. The Multi-Commentary Platform
The Multi-Commentary application provides a reading environment for exploring editions of
Ajax and accompanying commentaries. The platform itself, a fork of the Open Commentaries library from the New Alexandria Foundation, represents the critical text as a digraph whose nodes are text and edges are citations.
4
Further, this representation of the critical text and commentaries allows the reader to change the critical text while retaining all of the glosses across any number of selected commentaries, even if those commentaries were written using a different edition of the critical text.
Critical text(s). The primary text of the
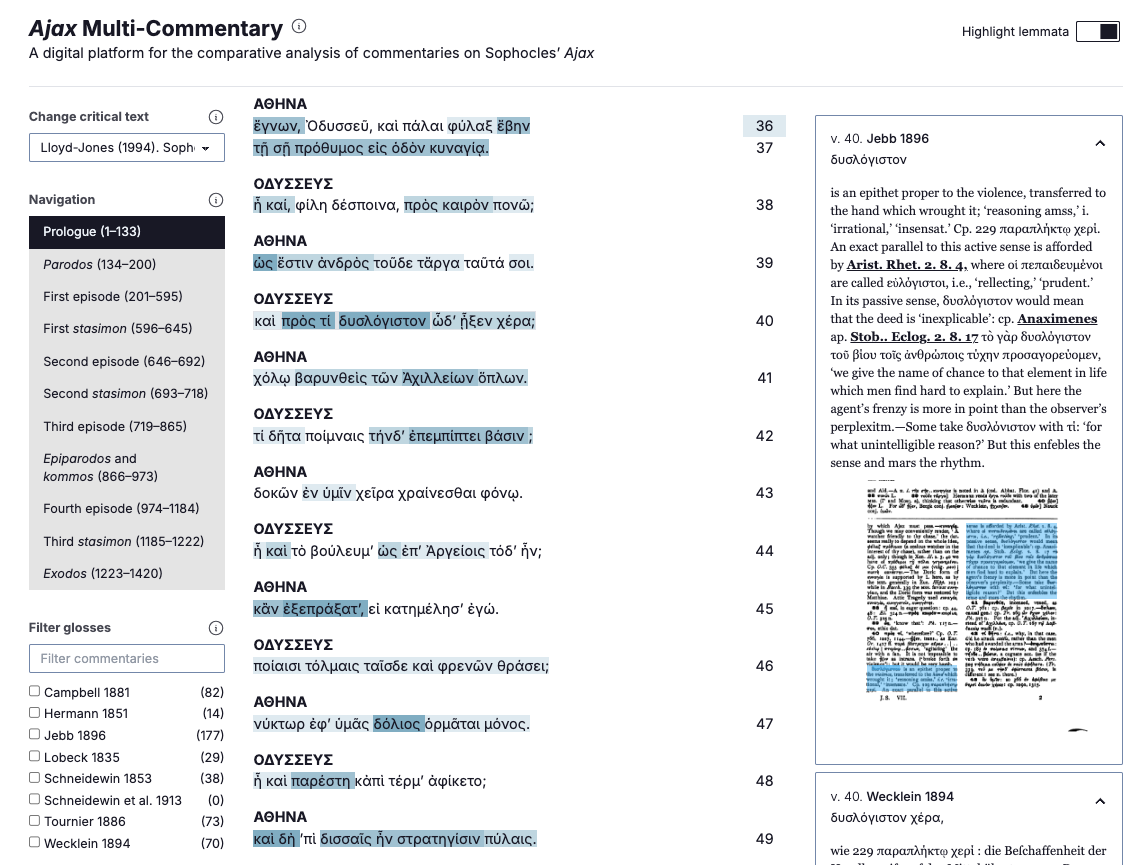
Ajax is displayed in the central column. Portions of the text to which one or more commentators have devoted a gloss in their commentary are highlighted in the text. Each highlighted region corresponds to the textual anchor of one or more glosses. Textual anchors on which more than one author commented are highlighted in a darker shade, creating a “heat map” effect that allows readers to spot heavily glossed passages at a glance. Further, since each commentator may disagree with regards to the critical reading of the text, readers of the Multi-Commentary will be able to change the critical text being displayed. This functionality makes it possible to see on which reading of the text a given gloss was based, which is essential for a proper contextualisation of each commentator’s work.
Commentary glosses. The commentary glosses that refer to the section of the text currently in focus are displayed to the right in the gloss viewer, which enables non-linear reading of commentaries. Non-linear reading is of primary importance when comparing glosses with one another, but it is currently one of the most time-consuming aspects of working with digitised commentaries. In fact, absent any indexing, the reader needs to find the relevant commentary page in a potentially large number of publications, a slow and laborious operation. In the gloss viewer, the reader has access to both the OCR transcription – which may have undergone manual correction – and page image, with highlighted regions corresponding to the lemma (if available) and gloss. Quick and direct access to the page facsimile is one of the key features of the Multi-Commentary, and its usefulness is especially apparent when it comes to older and more obscure commentaries, which may not be readily available in any Classics library.
Hyperlinking. Each of the glosses can reference any number of entities both within the critical text — such as when a commentator refers the reader to a previous or future line of the play — or external to it, such as when a commentator cites another literary work or refers to a historical or mythological person, place, or thing. The text processing pipeline (detailed above) identifies these entities, and the reading environment turns these identifications into hyperlinks either to other sections and possibly editions of the critical text or to other sources of open data (e.g., the Perseus digital library). These links drastically reduce the amount of page-flipping that scholars need to perform when following the networks of references that each commentary contains.
Bibliographic database. Bibliographies demonstrate the cumulative knowledge on which commentaries draw and which they create. The quality of the bibliography is also one of the main criteria for judging a commentary, as it shows the quality (thoroughness, multilingualism, age) of secondary literature sources consulted by the commentator. At the same time, it is rare that the bibliography of a printed commentary is exhaustive, given the abundance of existing literature and the space constraints of the printed medium. For this reason, the Multi-Commentary includes a bibliographic database. Its purpose is twofold: first, to make accessible in a single place any publication cited by previous commentators on the
Ajax, and second, to gather relevant bibliography that is not contained in the commentaries themselves. Each bibliographic item represents another citable entity in the hyperlinked network described above.
4.
4. Outlook
The Multi-Commentary platform we present in this paper will likely impact how future classical commentaries on Sophocles’
Ajax will be written, and opens up new perspectives for the digital future of classical commentary as a genre. First, the ability to refer directly to individual glosses by means of hyperlinks makes it possible to have
meta-commentaries, to use Heslin’s term, commentaries that comment on other commentaries – to which the reader has direct access – and that provide a historical perspective on the evolution of our knowledge about classical texts. Second, having a semi-automatic pipeline for processing digitised commentaries means that, in the near future, we could have Multi-Commentary platforms for classical works other than Sophocles’
Ajax, possibly interlinked to become a networked body of knowledge about classical texts.