
Advances in handwritten text recognition (HTR) combined with the availability of platforms like Transkribus and eScriptorium have supported a multitude of projects involved in automatically extracting information from images of historical documents. When recognizing information on a manuscript folio, many projects focus on the main text – it is not uncommon for this to be the object of study in the first place and, furthermore, extracting it tends to present a less complicated task for the computer. However, even if a project focuses only on the main text, other elements on the folio can still present complications. Segmentation models used for layout analysis may erroneously identify (sections of) marginalia, tables, or even graphics as main text, introducing errors when these regions are passed forward to be processed through HTR pipelines. Further, when paratextual material is itself the object of study, segmentation models capable of handling complex layouts are necessary to access this material at scale.
This study evaluates approaches to complex segmentation problems for the case of Arabic scientific and mathematical manuscripts. Such materials provide examples of complex layouts with multiple types of content, including but not limited to main text, marginalia, tables, diagrams, and illustrations. Improved access to this kind of data supports a variety of scholarly inquiries, from examination of mathematical diagrams to extraction of contemporary scholarship recorded in marginalia. 1
Figure 1: Folios 4b and 5b from “The Book of Fixed Stars” by Al-Sūfī (10th century) in MS Princeton, Garrett no. 2259Yq. These folios concern the constellations Ursa Minor and Ursa Major and are examples of layouts that combine main text, marginalia, and annotated illustrations.
The data used in the present study comes from two sources. The first is from the 2018 and 2019 competitions on Recognition of Historical Arabic Scientific Manuscripts, which afterwards deposited and licensed the competition training and evaluation data for further study (120 single folio images digitized in the Qatar Digital Library, joined by corresponding PAGE XML files). 2 This dataset has been adapted to use the SegmOnto controlled vocabulary in agreement with the other training data used in the study. 3
The second source is hand-annotated ground truth produced in this study for manuscripts from Princeton University Library’s Garrett Collection. This corpus contributes a greater variety of data, as this image set includes: (1) high resolution photographs produced in institutional digitization efforts, (2) digitized versions of microfilm reproductions, and (3) photographs taken by the camera of a personal mobile device. The first two types allow for evaluation of performance on a variety of institutionally-produced images; the latter for evaluation on images a researcher might rely upon when professionally-digitized images are not available.
A key challenge in producing effective segmentation models is creating the necessary ground truth. Segmentation models require large amounts of training data; further, training data for complex layouts often have a higher number of annotations per folio. This is time-intensive to produce, especially when the annotator must provide segmentation information for content in unusual shapes, content that wraps around other content, or content that intersects other content.
Current research takes several avenues in addressing this. First, the publication of more reusable data – particularly data annotated in a standardized way – provides researchers with a foundation to start from rather than prepare ground truth and models from scratch. 4 Second, improvements in segmentation technology see higher accuracy scores for smaller sets of training data. 5 Third, data augmentation methods and synthetic data can artificially increase the size of a ground truth dataset, providing more variety on which to train a model but with less work required for the initial curation of ground truth. 6
This short paper focuses on the third approach, applying augmentation methods such as geometric and color transformations to the complex layouts of Arabic scientific manuscripts. It compares the performance of segmentation models trained on augmented versus unaugmented ground truth across different categories of manuscript images: high resolution professional photographs, digitized microfilm images, and personal photography. To train the segmentation models, the present project uses the layout analysis system of Kraken, the engine beneath eScriptorium. 7
One challenge in training for complex layouts is that certain region types may appear significantly more frequently than others. This leads to imbalanced training data; the models trained on such material will likely perform poorly on rare classes. Depending on the researcher’s dataset, it may not be feasible to select a more balanced sampling of the training data to address this problem. Therefore, in addition to augmentation at the image-level of the dataset, the present project also evaluates data augmentation at the level of the annotated region. The workflow developed in this study allows the researcher to artificially increase the variety of training data available for otherwise rare region types. This is accomplished through Python scripts which automatically extract instances of rare classes in the ground truth dataset, apply transformations to those subregions, and add each transformed subregion to a suitable empty portion of a page image. 8 Transformations are randomly chosen from a selection defined as appropriate for the subregion and target page image in question (e.g., mirroring would not be suitable for region types that contain Arabic text, but rotation would be).
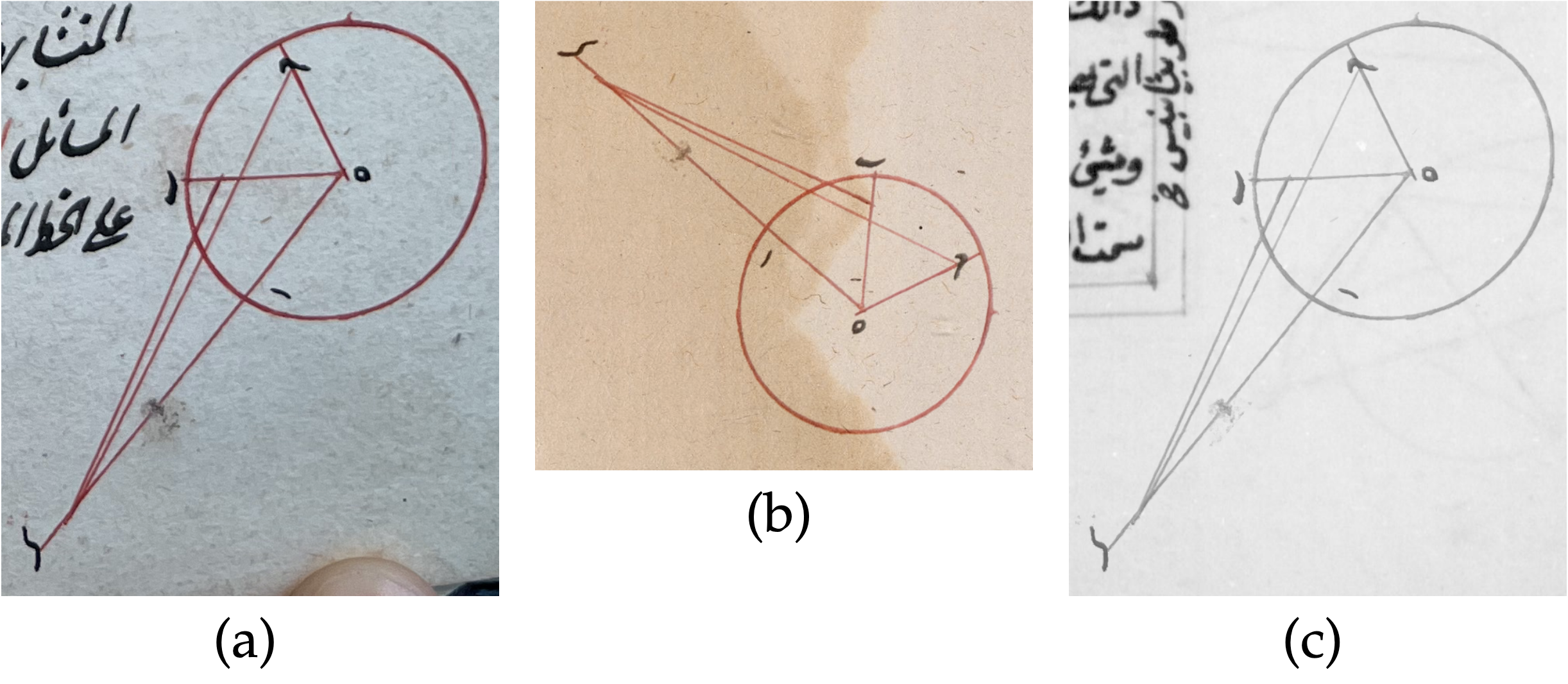
Figure 2: (a) Cropped image of a diagram from ground truth data for MS Princeton, Garrett no. 2975y, folio 50b; (b) that same diagram extracted from its original image, augmented with geometric transformations, and added to a different folio image to create augmented ground truth; (c) the same diagram extracted, augmented with color transformations, and added to a microfilm image.
The results documented in this paper offer insights into how page image types and qualities affect the results obtained from image segmentation technologies. They show the impacts of introducing more varied training data using different kinds of segmentation methods, and what proportion of unaugmented and augmented training data is most effective for these complex manuscript layouts. And they point to strategies which may serve future projects by reducing the cost of ground truth annotation needed to train segmentation models for unusual and complex layouts.
For instance, manuscript diagrams have received increasing attention in the field of Greek mathematics since Netz 1999 commented on the interdependence of diagram and text and the absence of any systematic study on Greek mathematical diagrams. For recent research using marginalia as documentary sources, see for instance the contributions in Görke and Hirschler 2011.
For competition overviews, see https://www.primaresearch.org/RASM2018/ and https://www.primaresearch.org/RASM2019/. For the results of RASM2018, see Clausner et al. 2018.
On SegmOnto, see Gabay et al. 2023.
See, e.g., the recent establishments of HTR-United (a catalog of training data sets made available for the creation of segmentation or HTR models) and SegmOnto (a controlled vocabulary for layout analysis).
E.g. Clérice 2022 and Kiessling 2022.
A recent study using this approach (Pack, Liu, and Soh 2022) examined the impact of training with augmented ground truth produced through degradation models using the software DocCreator (Journet et. al 2017). See also docExtractor in Monnier and Aubry 2020: this method works especially well when the generated synthetic data is used for pretraining, and the model then further refined on real training data for the task at hand.
For Kraken, see https://kraken.re. Transkribus is in the process of transitioning to a new layout analysis approach, Field Models, and is phasing out its previously-used P2PaLA engine. As such, this engine will not be evaluated in the present paper. On this, see https://help.transkribus.org/p2pala.
This is therefore augmented data (created from the existing ground truth) rather than fully synthetic data, and can be used in combination with existing synthetic data pre-training methods like that of Monnier and Aubry 2020.