1.
Introduction
2.
Recently, the advent of Large Language Models (LLMs) brought a paradigm shift in the realm of Natural Language Processing (NLP) and, as a consequence, in the Digital Humanities (DH). The fact that the massive amount of data from which these models are trained includes texts from several domains has shown to be an advantage for the capability of these models to accurately capture the meaning behind texts of several linguistic varieties and domains, including literary ones. As a consequence, NLP solutions based on LLMs have shown strong zero-shot performances on several tasks, such as Knowledge Extraction (KE) (Trajanoska et al., 2023). However, one of the main issues of LLMs is that they are prone to hallucinations. Since these models are trained through in-context learning, they are very capable of encoding relations between lexical entities but they are not able to instantiate properties between entities with declarative semantics, as in a Knowledge Graph (KG).
3.
One of the crucial aspects in the digitalization of literary texts involves extracting entities and relations from a corpus. Entity Linking (EL) is aimed at spotting references to entities and concepts in a text and subsequently determining which entry in a Knowledge Base this reference should be linked to (Kolitsas et al., 2018). Relations, instead, are obtained via Relation Extraction (RE), an algorithm which decides whether two entities are connected by one of many relations specified using a controlled vocabulary or an ontology (Cabot & Navigli, 2021). However, besides (Brando et al., 2016), there is a lack of EL and RE approaches specifically suited for documents formatted in XML/TEI.
4.
This research is aimed to provide a methodology for KE to be deployed on XML/TEI transcriptions of Italian literary texts, in order to extract formal, machine-readable representations of these documents which can be queried, explored and linked to external resources. The novelty of this approach is to address the limitations of current Relation Extraction models (RE) on Italian literary documents by employing ChatGPT (Openai, 2023) to transform unstructured texts into semi-structured formats, which can be easier interpreted by a general-purpose RE model. This abstract presents the following structure: the next section discusses the methodology, then a section will present the results obtained on a case study and the data considered as case study and future research steps will be outlined in the conclusion.
5.
Methodology
6.
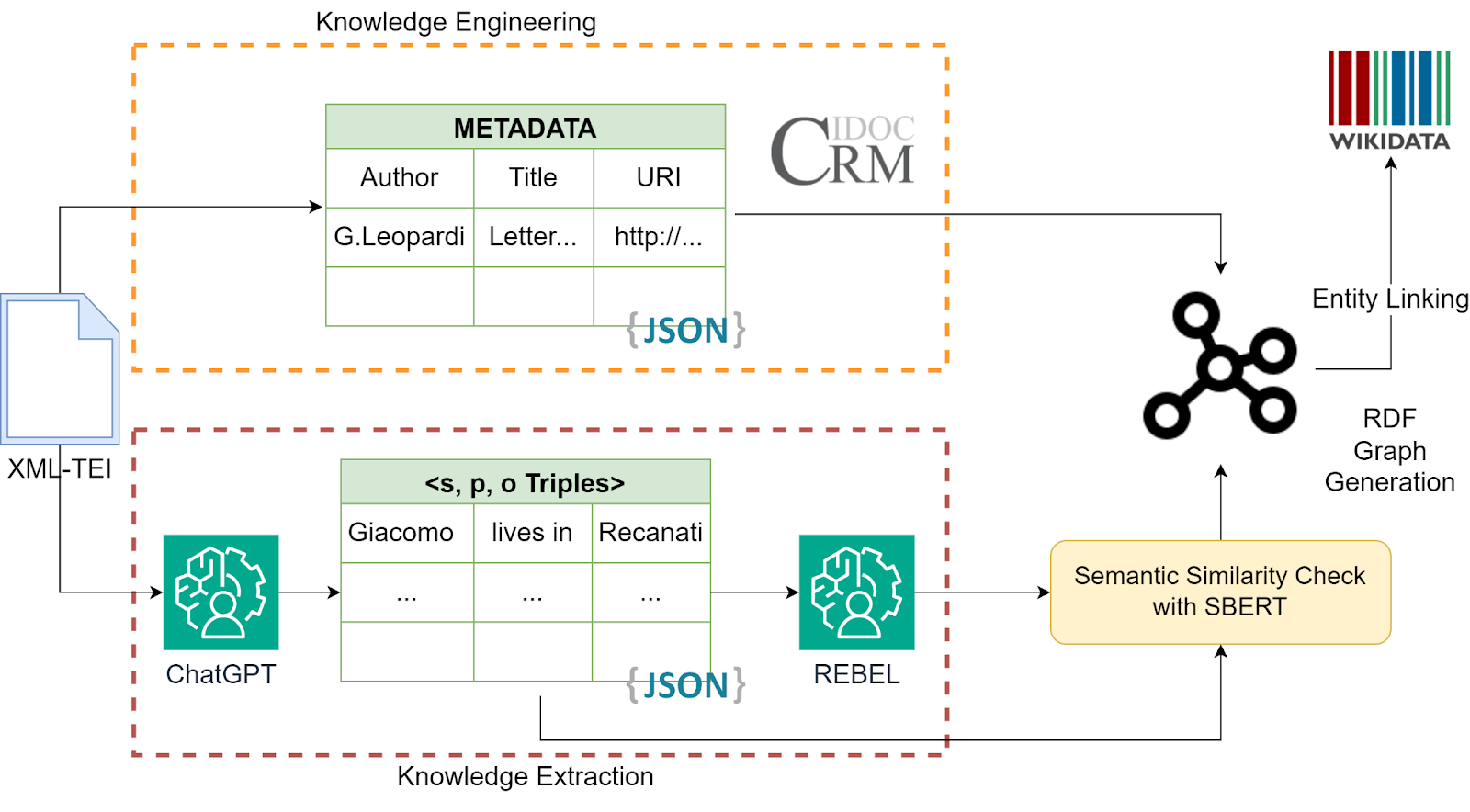
In order to extract entities and relations from a given transcription, we propose to employ a pre-trained RE model, namely REBEL (Cabot & Navigli, 2021). This model takes as input a piece of text and returns a list of strings of the form <head, relation, tail> where head and tail are two entities identified in the text and the relation is a property from Wikidata which connects them. The advantage of this model is to extract only relations which are semantically defined in the Wikidata KG. We decided to employ REBEL which is a monolingual RE model trained on English instead of his multilingual variant mREBEL (Cabot et al., 2023) due to better performances during our experiments. However, REBEL does not work for Italian literary documents, therefore an intermediate step was needed to generate synthetic data in English based on our data. In order to circumvent this problem, we decided to adopt an instruction-tuned LLM, e.g., ChatGPT4, in a preliminary step to preprocess the transcriptions into a JSON file of the following format: [ [entity1, relation, entity2], ...] where entities and relations are specified in English. For more details about the prompt used, source code is available on Github. Once a list of triples is produced as output by ChatGPT4, entities and relations are re-joined into a string and fed to REBEL in order to map the strings in English to RDF statements using Wikidata properties. In the last step, the output of REBEL is compared with the output of ChatGPT4 in order to find inconsistencies. This process is carried out by applying a threshold over the cosine similarity of the two strings encoded by a Sentence Transformer (Reimers & Gurevych, 2019). An overview of our approach is shown in Figure 1. In the final step, the extracted triples are integrated with possible metadata available in the input TEI transcription in order to disambiguate entities by leveraging already present identifiers from Wikidata, VIAF or GeoNames.
7.
7.1.
Figure 1: A schema of our approach
8.
Case Study and Results
9.
In order to evaluate our approach we chose as case study the Leopardian manuscripts available in the Cambridge University Digital Library (CUDL). This dataset comprises 41 letters, fully transcribed in XML/TEI and related to Giacomo Leopardi. Since this is not a ground truth for evaluating KE methods, we compared the percentage of correct triples obtained with our approach with those obtained using a multilingual end-to-end RE model, i.e. mREBEL on the letters. While our approach generated 19 correct triples out of 38, with a 50% of accuracy, the considered baseline generated only 4 triples out of 40 were correct. This noticeable improvement in accuracy suggests the usefulness of integrating multiple components into a KE pipeline to adapt RE tools to multilingual documents.
10.
Conclusions
11.
To conclude, this research shows a novel approach to combine LLMs and fine-tuned models for RE on Italian literary texts, by adopting a LLM to preliminary pre-process texts into natural language triples in order to simplify the RE task for the fine-tuned model. After RDF statements are extracted, the quality of the output KG is to be evaluated. For this task, specific metrics for KG quality control (Wang et al., 2021) can be borrowed, in order to evaluate the semantic, syntactic and linking accuracy of the extracted triples and to compare different models or prompts.
12.
References
13.
Brando, Carmen / Frontini, Francesca / Ganascia, Jean-Gabriel
(2016): "REDEN: Named Entity Linking in Digital Literary Editions Using Linked Data Sets", in: Complex Systems Informatics and Modeling Quarterly (7): 60. DOI: 10.7250/csimq.2016-7.04.
14.
Cabot, Pere-Lluís Huguet / Tedeschi, Simone / Ngomo, Axel-Cyrille Ngonga / Navigli, Roberto
(2023): “REDFM: a Filtered and Multilingual Relation Extraction Dataset”, arXiv, <http://arxiv.org/abs/2306.09802> [31/05/2024].
15.
Huguet Cabot, Pere-Lluís / Navigli, Roberto
(2021): “REBEL: Relation Extraction By End-to-end Language generation”, in: Moens, Marie-Francine / Huang, Xuanjing / Specia, Lucia / Yih, Scott Wen-tau (eds.): Findings of the Association for Computational Linguistics: EMNLP 2021. Punta Cana, Dominican Republic: Association for Computational Linguistics. 2370–2381, <https://aclanthology.org/2021.findings-emnlp.204> [31/05/2024].
16.
Kolitsas, Nikolaos / Ganea, Octavian-Eugen / Hofmann, Thomas
(2018): “End-to-End Neural Entity Linking”, in: Proceedings of the 22nd Conference on Computational Natural Language Learning. Brussels, Belgium: Association for Computational Linguistics. 519–529, <https://aclanthology.org/K18-1050> [31/05/2024].
17.
Openai
(2023): “ChatGPT: Optimizing Language Models for Dialogue”, in: archive.ph, <https://archive.ph/4snnY> [7/06/2024].
18.
Reimers, Nils / Gurevych, Iryna
(2019): “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks”, arXiv, <http://arxiv.org/abs/1908.10084> [31/05/2024].
19.
Trajanoska, Milena / Stojanov, Riste / Trajanov, Dimitar
(2023): “Enhancing Knowledge Graph Construction Using Large Language Models”, arXiv, <http://arxiv.org/abs/2305.04676> [31/05/2024].
20.
Wang, Xiangyu / Chen, Lyuzhou / Ban, Taiyu / Usman, Muhammad / Guan, Yifeng / Liu, Shikang / Wu, Tianhao / Chen, Huanhuan
(2021): "Knowledge graph quality control: A survey", in: Fundamental Research 1 (5): 607–626. DOI: 10.1016/j.fmre.2021.09.003.