-
Aumueller, Martin / Bernhardsson, Erik / Faitfull, Alec (2023):
ANN Benchmarks <https://ann-benchmarks.com> [09.05.2024].
-
Carion, Nicolas / Massa, Francisco / Synnaeve, Gabriel / Usunier, Nicolas / Kirillov, Alexander / Zagoruyko, Sergey (2020): “End-to-end Object Detection with Transformers”, in:
Computer Vision – ECCV 2020. Lecture Notes in Computer Science 12346: 213–229. DOI: 10.1007/978-3-030-58452-8_13.
-
Chen, Cheng / Zhuang, Yueting / Nie, Feiping / Yang, Yi / Wu, Fei / Xiao, Jun (2011): “Learning a 3D Human Pose Distance Metric from Geometric Pose Descriptor”, in:
IEEE Transactions on Visualization and Computer Graphics 17, 11: 1676–1689. DOI: 10.1109/TVCG.2010.272.
-
Chen, Haibo / Zhao, Lei / Wang, Zhizhong / Hui Ming, Zhang / Zuo, Zhiwen / Li, Ailin / Xing, Wei / Lu, Dongming (2021): “Artistic Style Transfer with Internal-external Learning and Contrastive Learning”, in:
35th Conference on Neural Information Processing Systems <https://proceedings.neurips.cc/paper/2021/file/df5354693177e83e8ba089e94b7b6b55-Paper.pdf> [09.05.2024].
-
Gonthier, Nicolas / Ladjal, Saïd / Gousseau, Yann (2022): “Multiple Instance Learning on Deep Features for Weakly Supervised Object Detection with Extreme Domain Shifts,” in:
Computer Vision and Image Understanding 214. DOI: 10.1016/j.cviu.2021.103299.
-
Impett, Leonardo / Süsstrunk, Sabine (2016): “Pose and Pathosformel in Aby Warburg’s Bilderatlas”, in:
Computer Vision – ECCV 2016 Workshops. Lecture Notes in Computer Science 9913: 888–902. DOI: 10.1007/978-3-319-46604-0_61.
-
Jadon, Shruti / Jadon, Aryan (2020):
An Overview of Deep Learning Architectures in Few-shot Learning Domain arXiv:1412.6980.
-
Johnson, Jeff / Douze, Matthijs / Jegou, Herve (2021): “Billion-scale Similarity Search with GPUs”, in:
IEEE Transactions of Big Data 7: 535–547. DOI: 10.1109/TBDATA.2019.2921572.
-
Kadish, David / Risi, Sebastian / Løvlie, Anders S. (2021): “Improving Object Detection in Art Images Using Only Style Transfer”, in:
International Joint Conference on Neural Networks. IJCNN 2021, 1–8. DOI: 10.1109/IJCNN52387.2021.9534264.
-
Knowlson, James R (1965): “The Idea of Gesture as a Universal Language in the XVIIth and XVIIIth Centuries”, in:
Journal of the History of Ideas 26: 495–508.
-
Li, Ke / Wang, Shijie / Zhang, Xiang / Xu, Yifan / Xu, Weijian / Tu, Zhuowen (2021): “Pose Recognition with Cascade Transformers”, in:
IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2021, 1944–1953.
-
Lin, Tsung-Yi / Maire, Michael / Belongie, Serge / Hays, James / Perona, Pietro / Ramanan, Deva / Dollár, Piotr / Zitnick, C. Lawrence (2014): “Microsoft COCO. Common Objects in Context”, in:
Computer Vision – ECCV 2014. Lecture Notes in Computer Science 8693: 740–755. DOI: 10.1007/978-3-319-10602-1_48.
-
Madhu, Prathmesh / Villar-Corrales, Angel / Kosti, Ronak / Bendschus, Torsten / Reinhardt, Corinna / Bell, Peter / Maier, Andreas K. / Christlein, Vincent (2023): “Enhancing Human Pose Estimation in Ancient Vase Paintings via Perceptually-grounded Style Transfer Learning”, in:
ACM Journal on Computing and Cultural Heritage 16, 1: 1–17. DOI: 10.1145/3569089.
-
Malkov, Yu A. / Yushunin, D. A. (2020): “Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs”, in:
IEEE Transactions on Pattern Analysis and Machine Intelligence 42, 4: 824–836. DOI: 10.1109/TPAMI.2018.2889473.
-
Mao, Hui / Cheung, Ming / She, James (2017): “DeepArt. Learning Joint Representations of Visual Arts”, in:
MM ’17. The 25th ACM International Conference on Multimedia, 1183–1191. DOI: 10.1145/3123266.3123405.
-
McInnes, Leland / Healy, John / Saul, Nathaniel / Großberger, Lukas (2018): “UMAP. Uniform Manifold Approximation and Projection”, in:
Journal of Open Source Software 3, 29. DOI: 10.21105/joss.00861.
-
Schneider, Stefanie / Vollmer, Ricarda (2023):
Poses of People in Art. A Data Set for Human Pose Estimation in Digital Art History arXiv:2301.05124.
-
So, Clifford K.-F. / Baciu, George (2005): “Entropy-based Motion Extraction for Motion Capture Animation”, in:
Computer Animation and Virtual Worlds 16, 3–4: 225–235. DOI: 10.1002/cav.107.
-
Springstein, Matthias / Schneider, Stefanie / Althaus, Christian / Ewerth, Ralph (2022): “Semi-supervised Human Pose Estimation in Art-historical Images”, in:
MM ’22. The 30th ACM International Conference on Multimedia, 1107–1116. DOI: 10.1145/3503161.3548371.
-
Sun, Jennifer J. / Zhao, Jiaping / Chen, Liang-Chieh / Schroff, Florian / Adam, Hartwig / Liu, Ting (2020): “View-invariant Probabilistic Embedding for Human Pose”, in:
Computer Vision – ECCV 2020. Lecture Notes in Computer Science 12350: 53–70. DOI: 10.1007/978-3-030-58558-7_4.
-
Tarvainen, Antti / Valpola, Harri (2017): “Mean Teachers are Better Role Models. Weight-averaged Consistency Targets Improve Semi-supervised Deep Learning Results”, in:
5th International Conference on Learning Representations. ICLR 2017.
-
van de Waal, Henri (1973–1985):
Iconclass. An Iconographic Classification System. Completed and Edited by L. D. Couprie with R. H. Fuchs. Amsterdam: North-Holland Publishing Company.
-
Wang, Jingdong / Sun, Ke / Cheng, Tianheng / Jiang, Borui / Deng, Chaorui / Zhao, Yang / Liu, Dong / Mu, Yadong / Tan, Mingkui / Wang, Xinggang / Liu, Wenyu / Xiao, Bin (2021): “Deep High-resolution Representation Learning for Visual Recognition”, in:
IEEE Transactions on Pattern Analysis and Machine Intelligence 43, 10: 3349–3364. DOI: 10.1109/TPAMI.2020.2983686.
-
Wang, Yingfan / Huang, Haiyang / Rudin, Cynthia / Shaposhnik, Yaron (2021): “Understanding How Dimension Reduction Tools Work. An Empirical Approach to Deciphering t-SNE, UMAP, TriMAP, and PaCMAP for Data Visualization”, in:
Journal of Machine Learning Research 22, 201: 1–73 <https://jmlr.org/papers/v22/20-1061.html> [09.05.2024].
-
Warburg, Aby (1998 [1905]): “Dürer und die italienische Antike”, in: Bredekamp, Horst / Diers, Michael (eds.):
Die Erneuerung der heidnischen Antike. Kulturwissenschaftliche Beiträge zur Geschichte der europäischen Renaissance. Gesammelte Schriften, 443–449. Berlin: Akademie Verlag.
-
Westlake, Nicholas / Cai, Hongping / Hall, Peter (2016): “Detecting People in Artwork with CNNs”, in:
Computer Vision – ECCV 2016 Workshops. Lecture Notes in Computer Science 9913: 825–841. DOI: 10.1007/978-3-319-46604-0_57.
-
Xu, Mengde / Zhang, Zheng / Hu, Han / Wang, Jianfeng / Wang, Lijuan / Wie, Fangyun / Bai, Xiang / Liu, Zicheng (2021): “End-to-end Semi-supervised Object Detection with Soft Teacher”, in:
IEEE/CVF International Conference on Computer Vision. ICCV 2021, 3040–3049. DOI: 10.1109/ICCV48922.2021.00305.
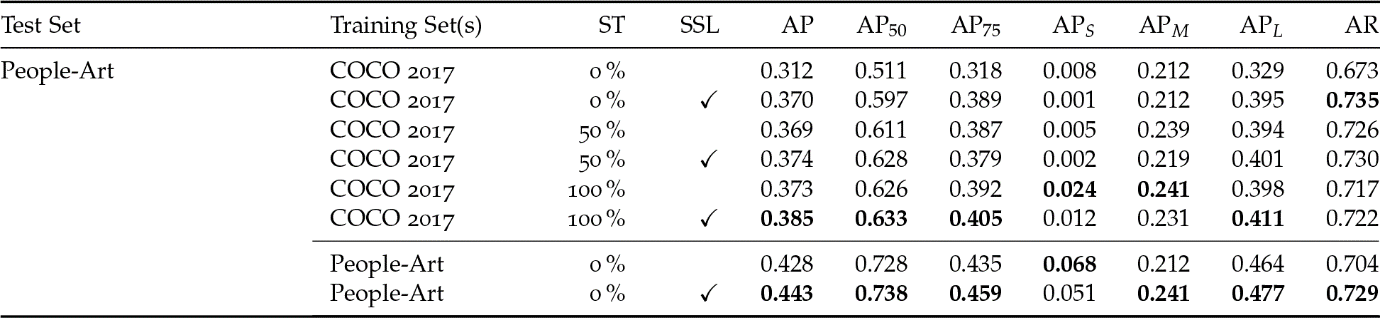
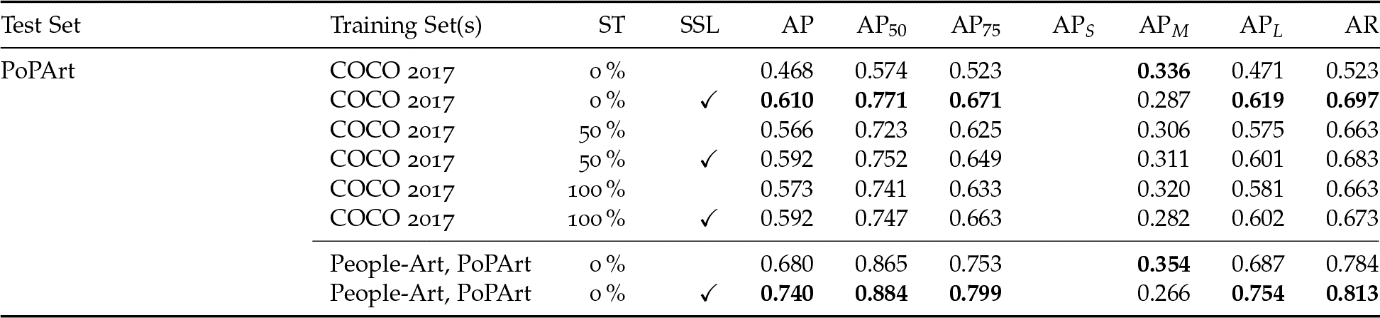
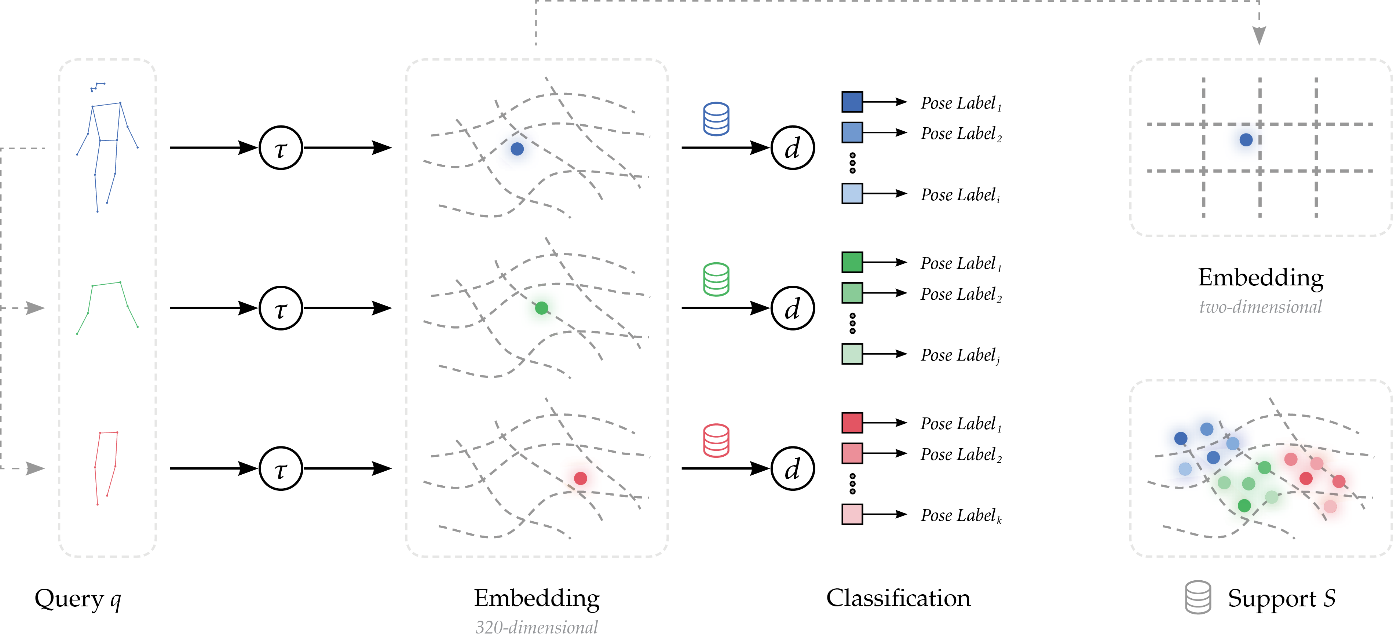
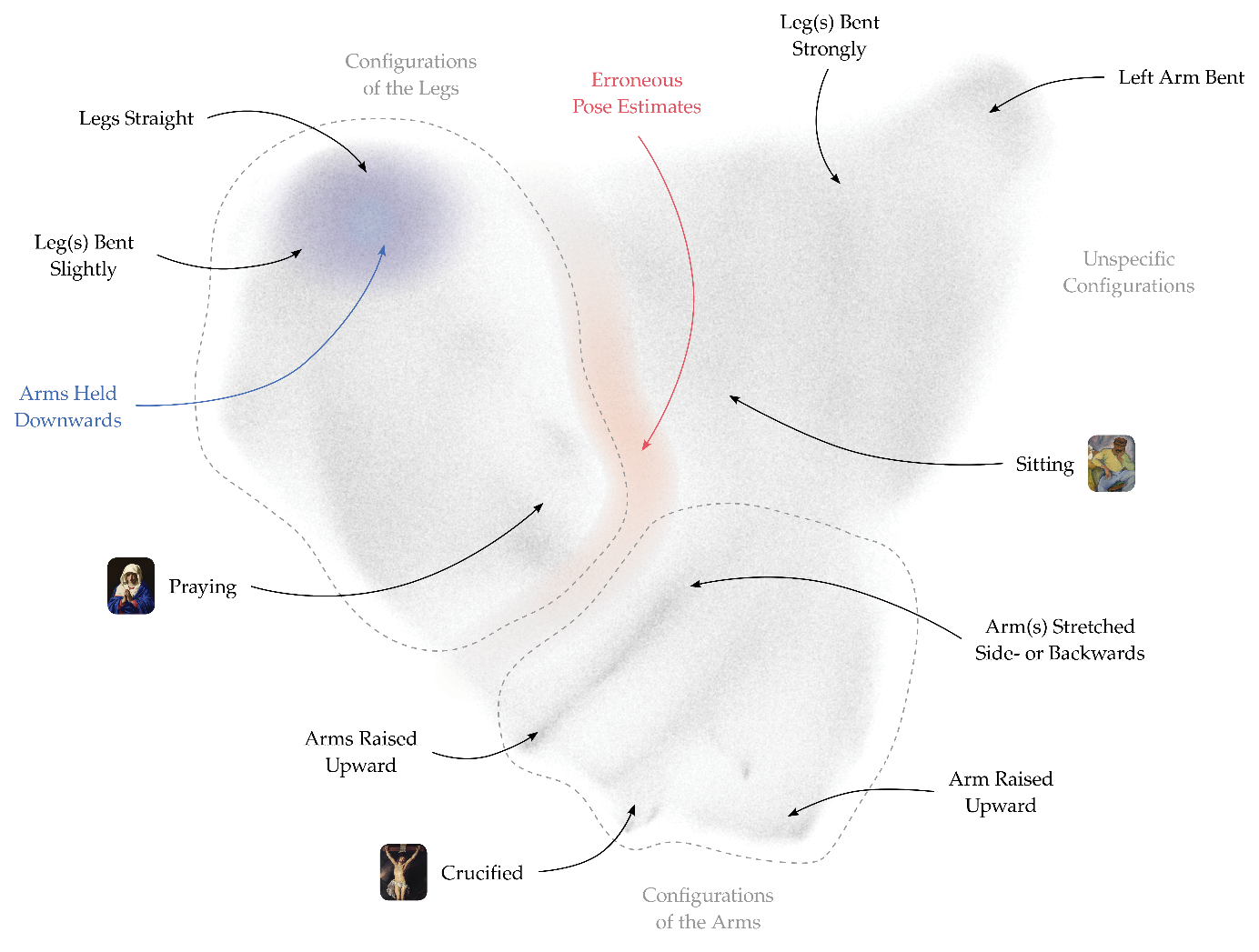
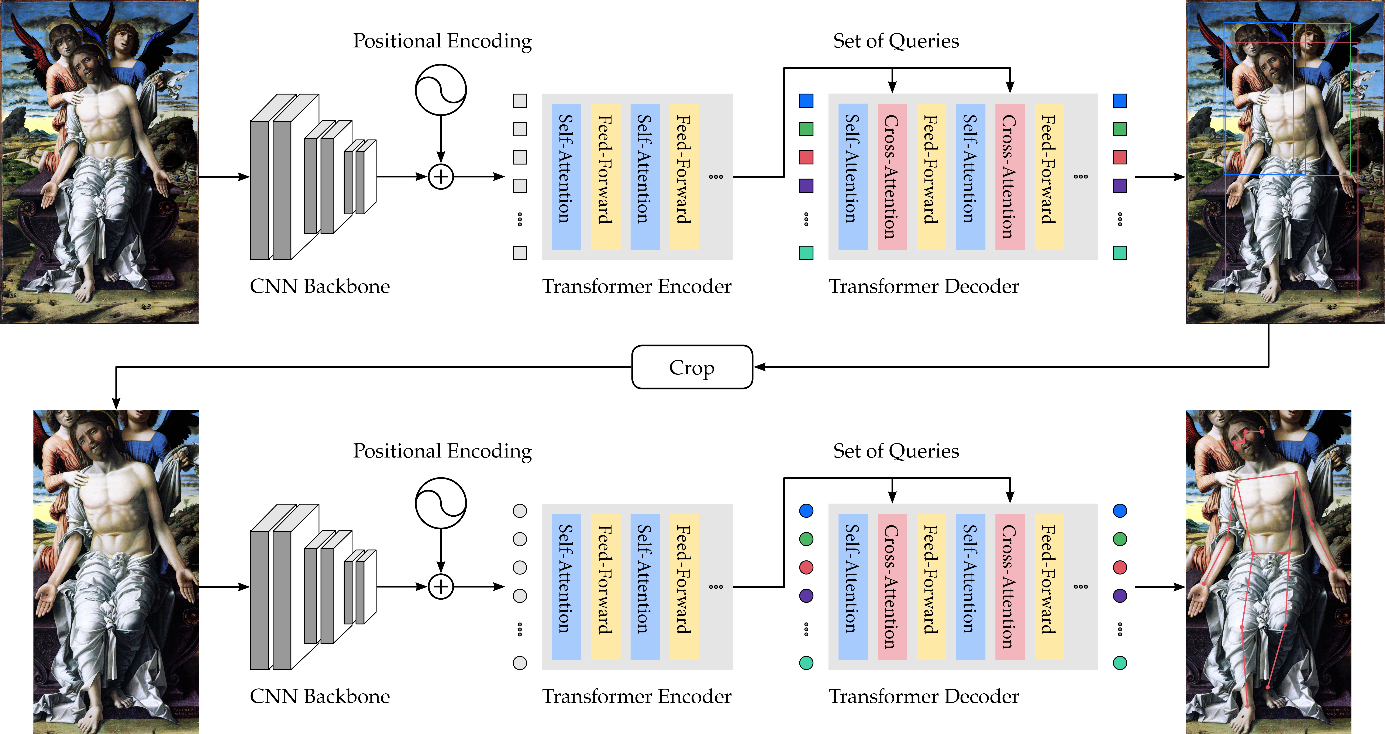 Fig. 1: Our approach to HPE first localizes human figures by bounding boxes; these boxes are then analyzed for keypoints (Springstein et al. 2022).
Fig. 1: Our approach to HPE first localizes human figures by bounding boxes; these boxes are then analyzed for keypoints (Springstein et al. 2022).