
Computational studies of literary space have been largely limited to tracking explicit spatial references, whether named entities (Piatti 2016; Evans and Wilkens 2018; Taylor and Gregory 2022) or seed terms like “street” (Bologna 2020; Schumacher 2023; Grisot and Herrmann 2023; Soni et al. 2023). Absent such markers, it remains difficult, except by hand-tagging (Bushell et al. 2017), to establish where a text is set. Current methods cannot determine, for example, whether a dialogue within a novel takes place in a kitchen unless the speakers themselves say “kitchen.” Similarly, nineteenth-century British fiction is full of domestic spaces that have a still-underspecified link to discourses of domesticity, even as scholars argue for the importance of this period in constructing both (Auerbach 2003; Gilbert and Gubar 2000; Armstrong 1987; McKeon 2005). As such, the link between domesticity as gendered, raced, and classed discourse and domesticity as fictional and material space is more tacit than textured (Armstrong 1987; Marcus 2009).
Our study productively unites these two gaps. We join them because this period’s “separate sphere” of domestic space corresponded with a “realist,” naturalized representation of such space (Cohen 2017; Wall 2006; Wagner 2021), a cultural history that simplifies contested theorizations of literary space (Bakhtin 1981; Zoran 1984; Jameson 1991; Bachelard 1994; Tally, Jr. 2013). In computationally modeling Victorian domestic space, we need only ask: is this passage set in a home?
That mimetic approach lets us train a machine-learning (ML) model that can accurately distinguish if a passage is set in a domestic space regardless of whether it mentions words like “house.” We fine-tuned the English BERT model (Devlin et al. 2019) with manually annotated training data from a corpus of 2,887 nineteenth-century British and Irish novels pulled from the University of Illinois libraries and Chadwyck-Healey Nineteenth-Century Fiction (Heuser and Le-Khac 2012; Chadwyck-Healey and ProQuest). Below, we introduce our model, which offers new computational approaches to literary space and domesticity.
Annotation of Training Data
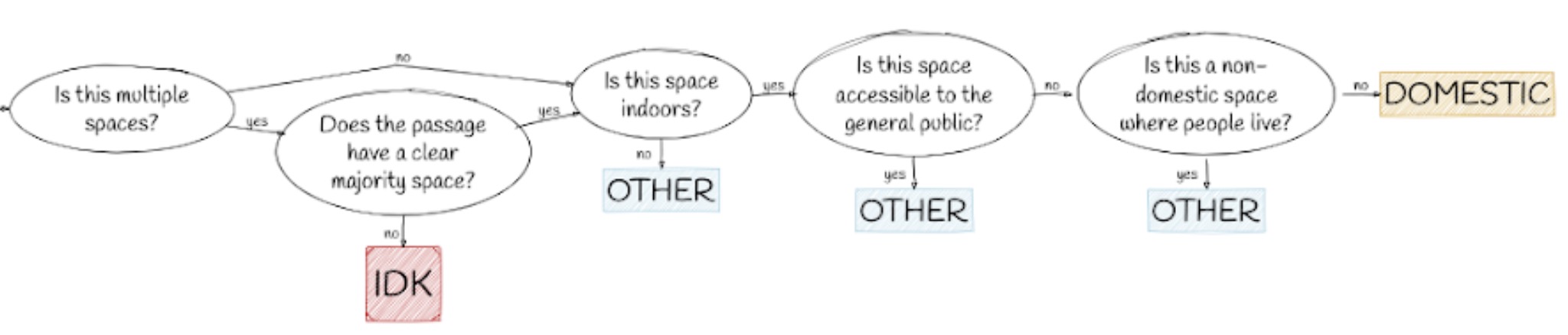
Drawing on our knowledge of the period’s literary history, we, a team of experts in literary studies, iteratively crafted annotation guidelines, considering 450 annotations of 90 passages over three rounds of discussion (Reiter 2020). To produce useful training data, we only included unambiguously domestic interiors, though we hoped our eventual model would capture domestic space more holistically. Figure 1 visualizes our final annotation guidelines as a flowchart.
Figure 1: Annotation guidelines as a flowchart. “Trash” is for unusable passages (e.g., OCR errors); “Other” for those not set in domestic space; “IDK” for those where it is impossible to be certain if they are in domestic space or not; and “Domestic” for those set in domestic space.
We produced 3,657 annotations of 1,375 six sentence passages, settling on that size to balance speed and accuracy. Our passages included those likely to be set in domestic space, those set in non-domestic spaces, and a random selection.
Our inter-annotator agreement (IAA) aligns with past research. Because our team consisted of seven annotators with an uneven overlap, we measured IAA with Krippendorrf’s alpha (Krippendorrf 2018). We achieved an alpha of .58, below Krippendorrf’s suggested cutoff of .8. However, alpha did not vary across pairs of annotators, meaning we had no rogue annotators (De Swert 2012), and qualitative analysis did not show systematic deviations. Instead, our alpha demonstrates the underlying ambiguity of determining literary space, as scholarship has long observed (Soni et al. 2023; Mani et al. 2010; Wilkens 2013).
To produce final training data, each of our 1,375 passages was hard-coded as “Domestic,” “Other,” or “Trash” according to the majority of its annotations. 221 passages had no majority due to annotators’ uncertainty; we withheld 104 of these to make a test set, examining the full novel to create gold standard tags. We supplemented the test set with 500 more annotations of 100 randomly selected passages.
Training and Evaluating a Model
Although our annotations illuminated points of agreement among field experts in literary studies, our goal in this project was ultimately to train a ML model capable of discerning whether a (six-sentence) passage was set in a domestic space. We had two objectives for our model. First, we wanted it to classify all passages from our corpus and provide large-scale insights into historical changes across our corpus. Second, while our annotation guidelines prioritized explicit cues for determining setting, we hoped our model would identify passages set in domestic space if they contained content frequently associated with such spaces. For example, our guidelines did not include gardens as domestic spaces–but if passages set in gardens contained dialogue resembling that in parlors, then the model, with its generalized language features, would classify them as domestic.
While we tested a variety of interpretable classification models, including logistic regression and discriminant function analysis, they produced poor results. We therefore turned to a TensorFlow-based model using the Keras API (Chollet et al. 2015). Given our relatively sparse data for training embedding models and the well-defined sentences within our passages, we adopted a transfer learning approach using Google's multilingual sentence encoders (Cer et al. 2018).
On a hard-classification task (i.e., assigning passages to “Domestic”, “Other,” or “Trash”), the transformer-based sentence encodings performed surprisingly well. We knew from annotating that this was a difficult task, but the model achieved an accuracy rate of 83% (validated with our withheld test data to 80%) over 20 epochs (Figure 2).
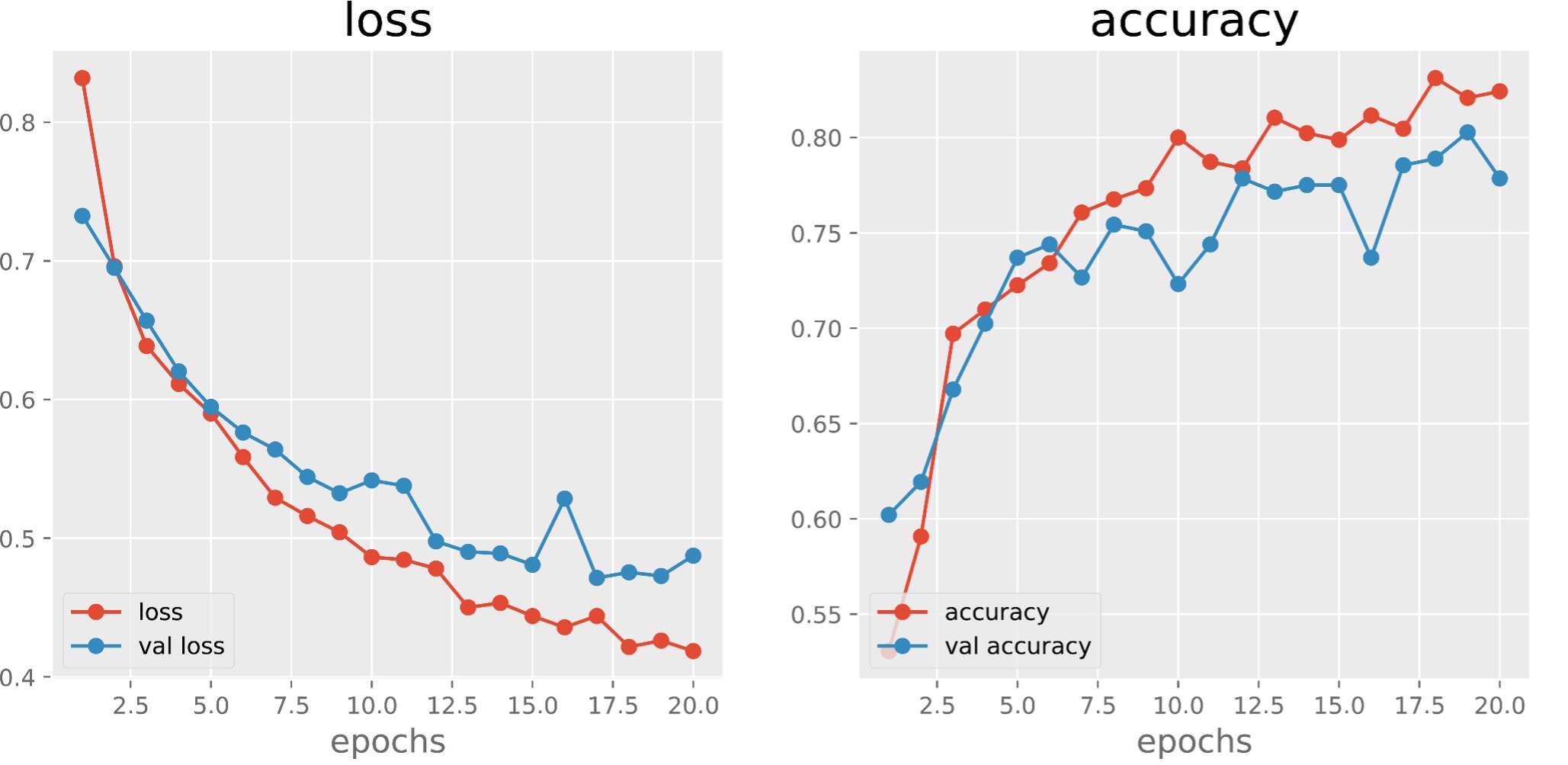
Figure 2: Loss and accuracy for training (red) and validation (blue) data across the 20 epochs of the TensorFlow sentence encoding model.
Although the hard-classification results were better than expected, our results improved further when we returned the posterior probabilities of group membership for each passage. Figure 3 shows the model's assigned probability that each passage is set in a domestic space, grouped by the majority-agreement hard tag. For “Domestic” passages, the posterior probabilities are rarely below 30% and almost never below 10%; the converse holds for “Other” and “Trash” passages. Given our IAA, we anticipated some misclassification. Further, since we wanted the model to reveal passages set in domestic spaces outside our narrow guidelines (e.g., gardens), some misclassification is actually desirable. Analysis of the posterior probabilities therefore proved encouraging.
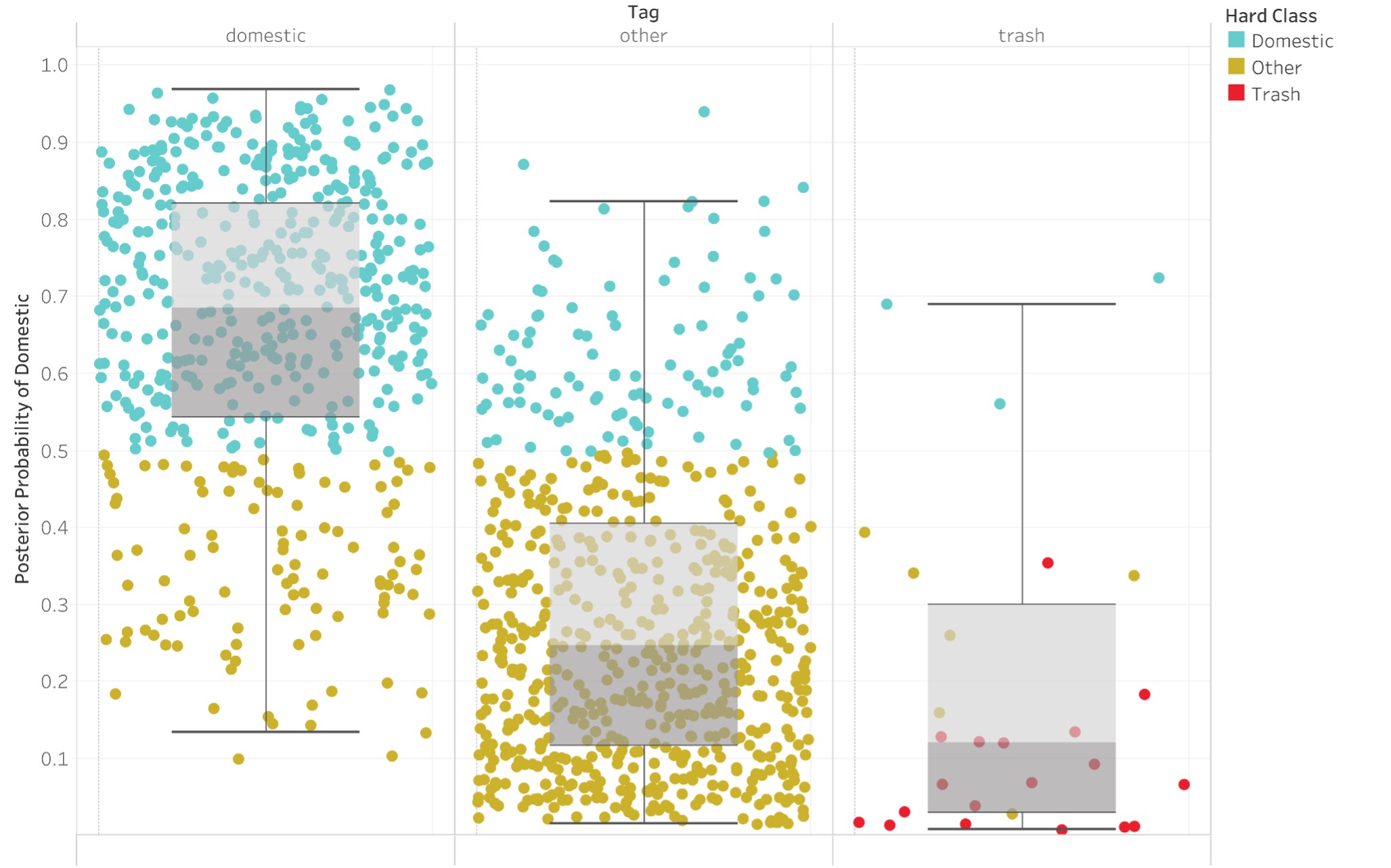
Figure 3: Probability of each passage being domestic according to our model. Tag represents the annotated passage type, while the y axis shows the probability of the passage being set in a domestic space. Color indicates the hard classification of each passage according to the model.
To validate the model, we sampled 120 new passages from the corpus, annotated them, and classified them using our model. Annotators agreed with the model in 85 cases (71% agreement), superior to our original IAA. Examining the outputted probabilities again strengthens the results. In 84 cases, the model rated the probability of the passage being “Domestic” above 70% or below 30%, and the annotators and model agreed on 82% of these more certain cases. The model assigned the remaining passages “Domestic” probabilities between 40% and 60%, indicating its high uncertainty, and here, the annotators and model only agreed 44% of the time. Thus, the vast majority of disagreement occurred in highly ambiguous passages that the model itself was uncertain about.
Use Cases
In applying the model to our corpus, we were excited to find that our model is sensitive to discursive signs of domestic space, not just literal markers. For example, it correctly detects more domestic space in Jane Austen’s Sense and Sensibility (Figure 4) than Walter Scott’s Waverley (Figure 5). Austen writes lots of dialogue but little description (Xu 2011), yet the model recognizes her extremely domestic settings, as we verified in examining individual passages.
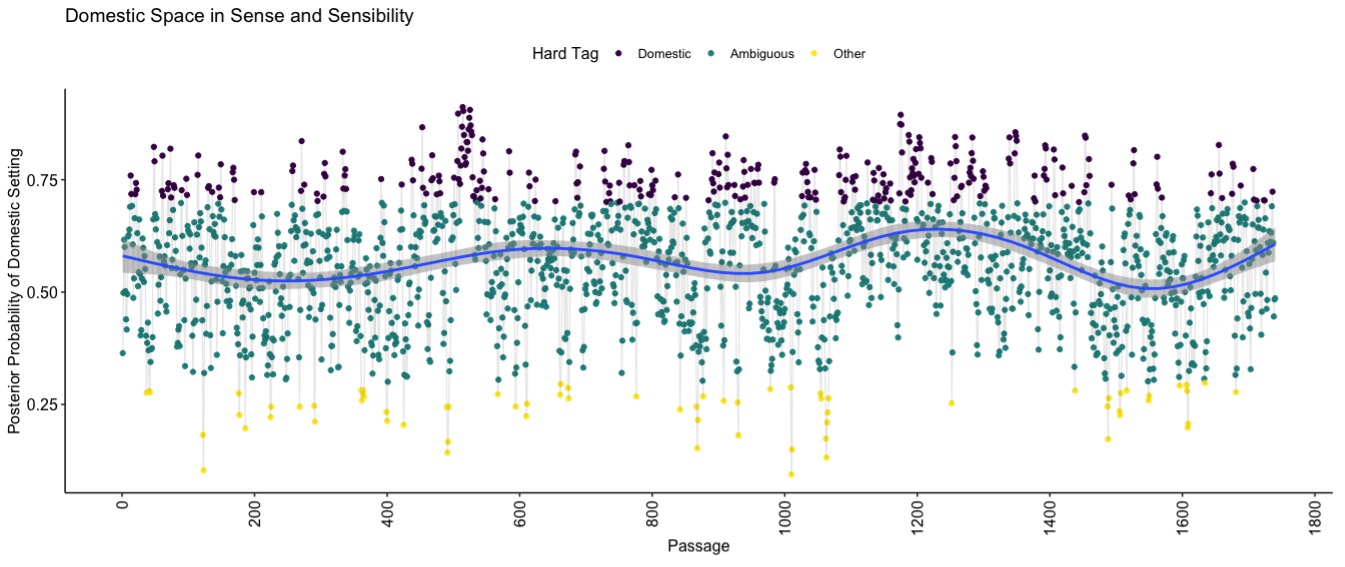
Figure 4: The posterior probabilities that six-sentence passages from Jane Austen's Sense and Sensibility are set in domestic space, per our model. The six-sentence windows overlap in the middle to avoid overlooking segments of highly domestic or non-domestic text. Each passage’s posterior probability is marked with a dot, color-coded to indicate what its hard tag would be. The curve is a LOESS regression showing trends in domestic space over narrative time.
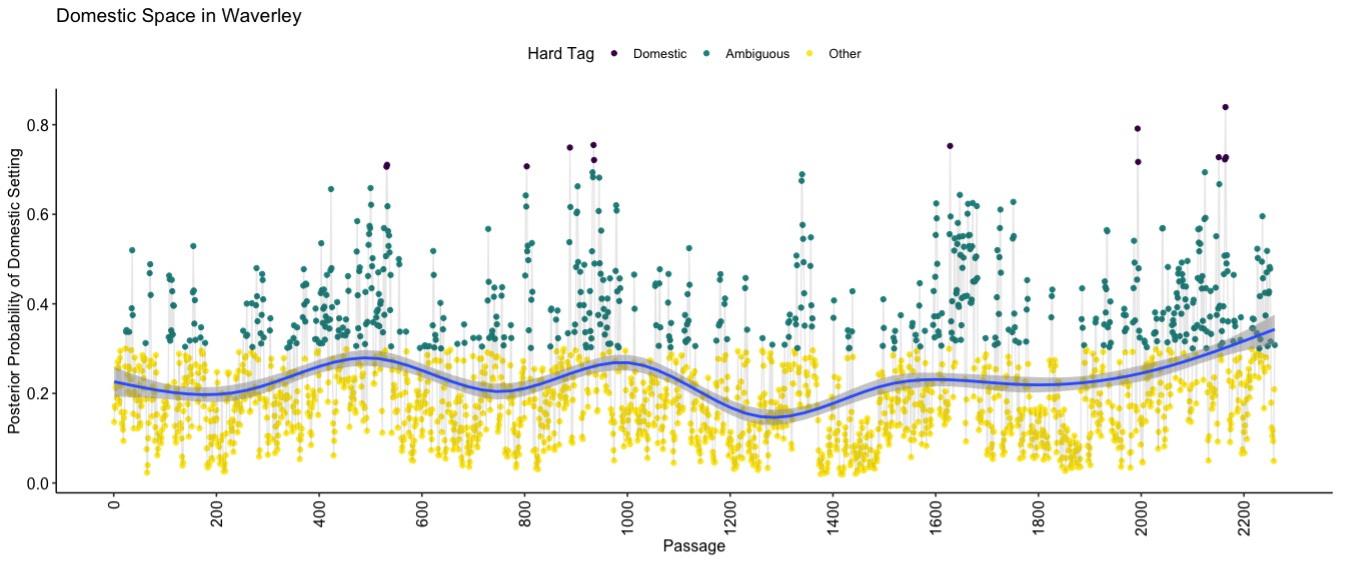
Figure 5: The posterior probabilities that six-sentence passages from Walter Scott’s Waverley are set in domestic space, per our model. See Figure 4 for details.
The model’s evaluation of Charlotte Brontë’s Jane Eyre, a touchstone in connecting domestic space to empire (Spivak 1985; Meyer 1996; David 2002), shows how it helps interpret individual texts. We used the posterior probabilities to classify passages into our annotation categories, then applied a Fisher’s exact test to find which words were most distinctive of “Domestic” and “Other” passages (Algee-Hewitt et al. 2020). We find that domestic space in this novel is discursively tied to women, materiality, and labor (“bid”) (Cuming 2013; Wagner 2021), while non-domestic passages are linked with men, Christianity, empire, and travel (Table 1). Our model brings us back to the chronotope: in these words and the novel’s plotting of domestic space (Figure 6), we see a struggle between the chronotopes of the road and the home.
Table 2: Most distinctive words of "Domestic" and "Other" passages in Jane Eyre per a Fisher’s exact test with p < .01. These terms occurred the most disproportionately across the tagged passages relative to the rest of the text.
| “Domestic” Words | “Other” Words |
| contented | crag |
| sleeping | toil |
| crib | missionary |
| tray | traveller |
| supper | heath |
| wake | deeply |
| curtains | faithfully |
| sophie | iron |
| amy | lane |
| bid | horse |
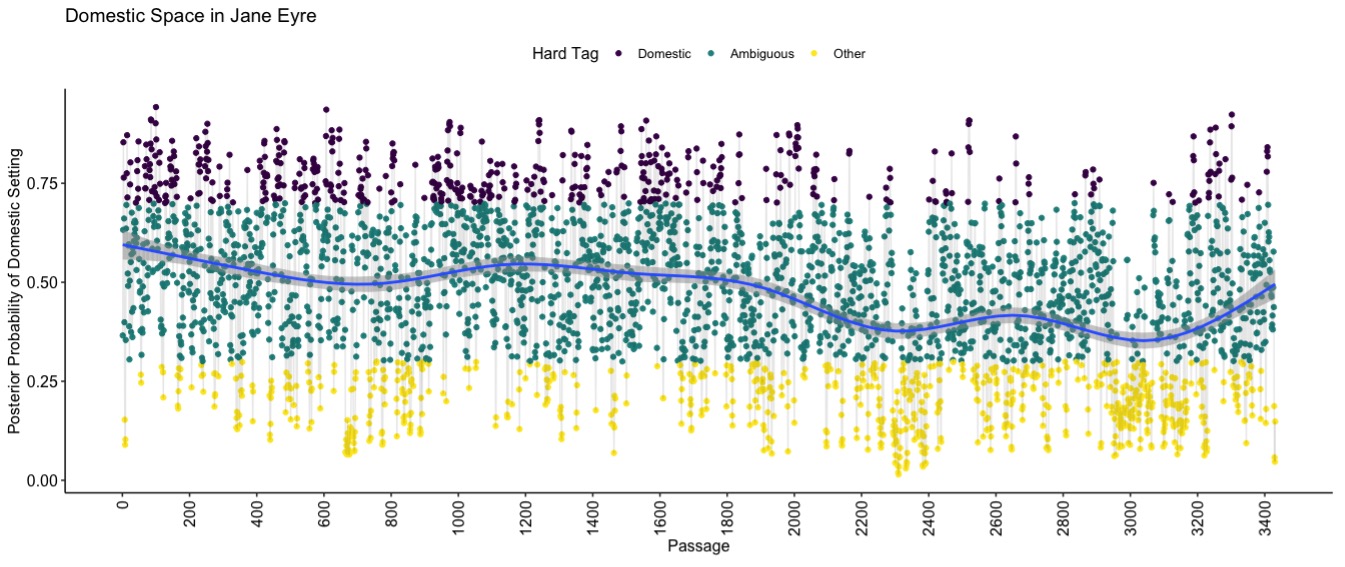
Figure 6: The posterior probabilities that six-sentence passages from Charlotte Brontë’s Jane Eyre are set in domestic space, per our model. See Figure 4 for details.
Given the model’s accuracy in analyzing individual texts, we leveraged it to explore historical trends across our corpus. Figure 7 shows the classification results for 288,700 passages from our corpus (100 passages sampled from our 2,887 novels), averaging the probabilities of the sampled passages in each year. A subtle but clear trend emerges: the increasing presence of domestic space in the British novel over the nineteenth century, with sampled passages growing about 10% more “Domestic” from 1800 to 1900. The overall trend and specific patterns (e.g., the bump in domestic space post-1840) add nuance to scholars’ claims about the history of domestic space (Armstrong 1987).
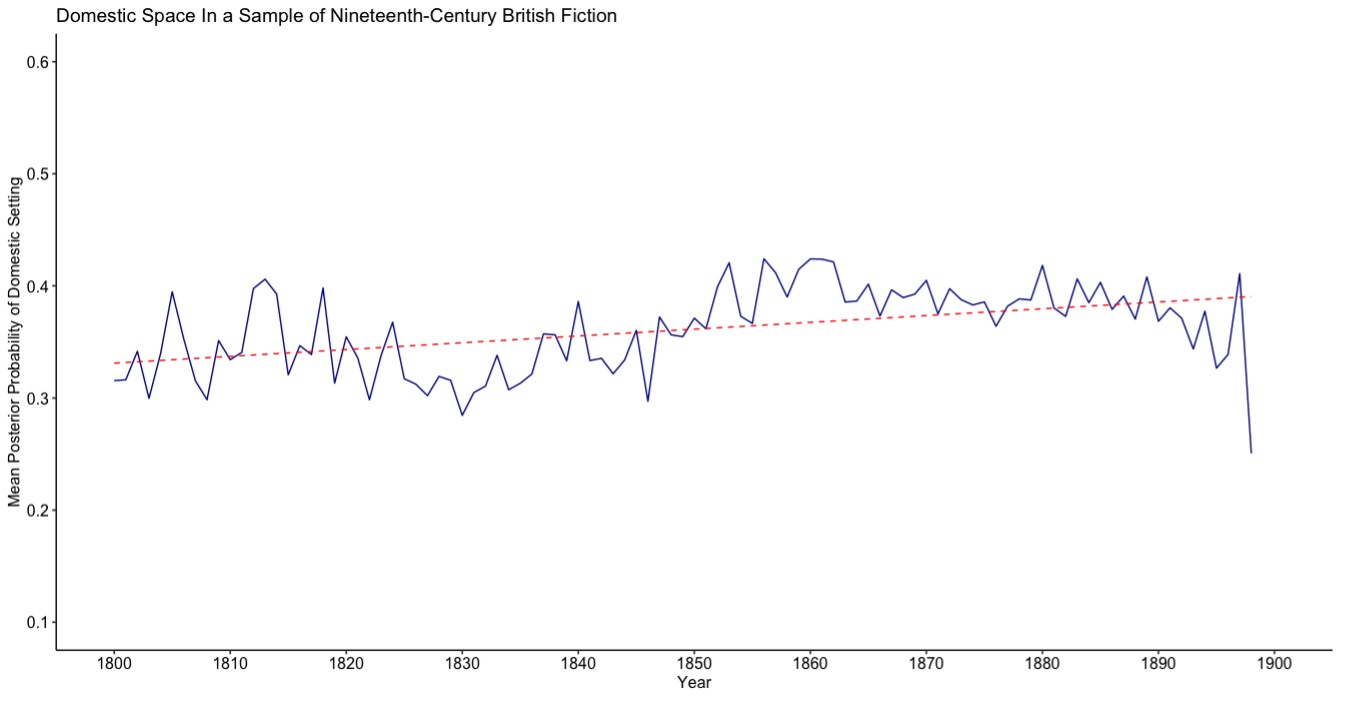
Figure 7: Classification of domestic space over time in a sample from every novel in our corpus. The y-axis indicates the mean of the probabilities of all passages sampled in each year. The solid line shows the value in each year and the dotted line highlights the trend with a linear regression.
Conclusion
Using a theoretically- and historically-sensitive operationalization and human annotations, we have presented a BERT model capable of identifying whether six-sentence passages from nineteenth-century British novels are set in domestic spaces. The model is surprisingly accurate, especially when we examine its posterior probabilities, and it is able to identify the setting of passages even without named entities or explicit terms, a significant advance in computational literary studies. It facilitates interpretations of both individual texts and whole corpora, enriching Victorian studies with more concrete, large-scale arguments about the relationship between literary space and colonial, gendered, and classed discourses of domesticity. In future work, we hope to further probe the relationship between domestic discourses and literary space, as well as to generalize our process to computational analyses of other spaces.