Semantics of Empire: Machine Translation of Ottoman Turkish into English
T his paper investigates the use of artificial intelligence (AI) for translating historical sources. We study the translation of Ottoman Turkish (OT) into English through two related questions. One, can we translate OT with relative success using neural machine translation (NMT) approaches and large language models (LLMs)? Two, how does the use of historical data complicate our understanding of AI models?
Our motivation is to enhance the availability of Ottoman texts in undergraduate classrooms. History programs in North America predominantly operate in English and teach primary sources either originally produced in English or translated into it. As such, translation determines whose histories are taught at the undergraduate level. In Ottoman studies, the decision to translate a text has historically been intertwined with the Orientalist scholarship of the 19th and 20th centuries. Recent publications attempt to overcome this dearth of sources (Casale 2021; Karateke / Anetshofer 2021). Nonetheless, translation of Ottoman sources remains not only a challenging and time-consuming task but also an academically under-valued one. Since incorporating primary sources and perspectives from otherwise-marginalized communities is crucial for diversifying history education, this paper explores whether AI models could lower the barriers to translation by acting as first-pass translators.
Ottoman Turkish (OT), a historical and primarily written language, presents a compelling case for computational research. OT was the official language of the Ottoman Empire (1299-1923). Although based on Anatolian Turkish, OT was written in Arabo-Persian script and contained words and phrases adapted from Arabic and Persian (Buğday 2009). Moreover, it displayed certain syntactic forms, such as the Persian ezafe or genitive case, no longer used in Turkish. After the dissolution of the Ottoman Empire, the Republic of Turkey passed the Alphabet Reform in 1928 (Lewis 1984; Zürcher 2004), which implemented the Latin alphabet for Turkish and the adaptation of new vocabulary to replace Arabo-Persian originated phrases. Over the last century, the language changed enough that even native speakers of Turkish can no longer innately understand OT. This also impacts natural language processing (NLP) tools developed for Turkish. Despite Turkish becoming a better-resourced language over the last decade, OT still remains low-resourced in NLP (Özateş et al. 2024).
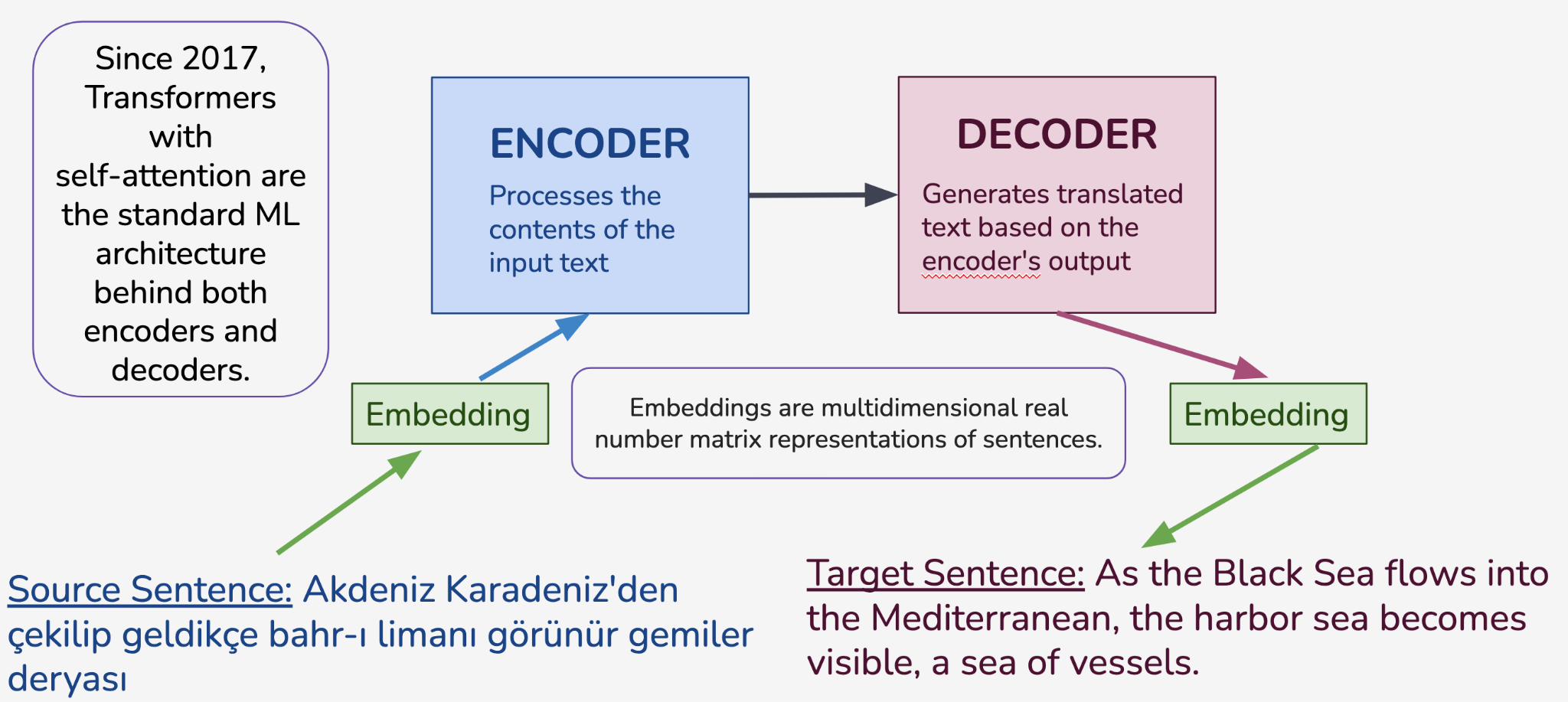
We tested two approaches to translate OT into English: training a neural machine translation (NMT) model and prompting large language models (LLMs). NMT is a sequence-to-sequence task in which a sentence is encoded in the source language and its translation decoded in the target language.
Low-resourced languages suffer from lack of existing data to train NMT models (Bala Doumbouya et al. 2023; Nekoto et al. 2020), which can be ameliorated through transfer learning methods (Zoph et al. 2016) or multilingual approaches. To the best of our knowledge, there is no MT system specifically designed for OT-EN translation and no reliable dataset for Ottoman-English MT model training 1 .
Dataset size (Koehn / Knowles 2017) and domain (Luong / Manning 2015) directly impact the performance of all NMT systems. The meaning of a word and its translation changes in different domains. A model trained on parliamentary records, news, Internet content and other contemporary texts do not perform well on historical or literary data. Initially, we created our own OT-EN training data with 4,078 sentence pairs from scholarly editions. However, a small custom training dataset was not sufficient for the infamously data-hungry Transformer architectures (Vaswani et al. 2017). Thus, we expanded our dataset with 52,229 Turkish-English sentence pairs from novels. We identified Turkish novels, particularly historical ones, with English translations, as these novels often contain words more commonly found in Ottoman texts and sometimes even approximate Ottoman syntax. This intervention allowed us to create a much larger dataset while remaining close to the domain of OT.
After compiling a raw corpus of 13 novels, we transformed them into MT datasets, which consist of bilingual sentence pairs. Transforming long-form parallel texts into semantically aligned sentence pairs falls under the domain of sentence alignment. Sentence alignment is the task of finding matching sentences in two parallel documents (Xu et al. 2015). A sentence alignment algorithm parses through parallel texts calculating the similarity of sentences in the source text with those in the target set to determine which sentence or sentences correspond to one another. Often used in the context of MT, sentence alignment could be a one-to-one match, meaning one sentence in the source text is translated as exactly one sentence in the target text or one-to-many, many-to-one, many-to-many or a sentence might be omitted in the translation or a new sentence might be inserted by the translator. After testing various methods, we used the SentAlign (Steingrimsson et al. 2023) algorithm and Language-agnostic BERT Sentence Embeddings (Feng et al. 2022).
| Dataset Name | Number of Sentence Pairs |
| Turkish Novels | 52,229 |
| Ottoman 1: Felatun Bey | 2,694 |
| Ottoman 2: Ahmed Resmi | 425 |
| Ottoman 3: Osman Agha | 755 |
Of the 3 works in OT, we identified Osman Agha’s memoirs as our ultimate test set. Translated into English in 2021 as Prisoner of the Infidels: The Memoirs of Osman Agha of Timişoara, the historical manuscript (British Library, Or. 3213) was completed in 1724 by the Ottoman soldier Osman Agha himself. It consists of his experiences during the 11 years he spent as a prisoner of war in Austria. Moreover, unlike many historical bi-text editions (Menchinger 2011), Osman Agha’s memoirs were transcribed (Koç 2020) and translated (Casale 2021) by different scholars. This means that this work does not exist as parallel data and we can be certain that even if it was seen in the training data of LLMs, the English and Ottoman copies were never placed together.
For NMT training, we experimented with fine-tuning a state-of-the-art Turkish-English NMT model, Opus-MT from Helsinki NLP (Tiedemann 2020, https://huggingface.co/Helsinki-NLP/opus-mt-tc-big-tr-en). We fine-tuned the Opus-MT model twice with different parameters on our novel dataset and tested its performance on all 3 Ottoman datasets. Finally, we implemented a multilingual joint fine-tuning approach (Das et al. 2023) with the same model, combining the Turkish novels and the two Ottoman datasets leaving Osman Agha aside as the test set. Our initial findings indicate that multilingual NMT training shows great potential. Our fine-tuning increased the baseline NMT score on an OT test set from 2.83 to 3.87 in BLEU score (Papineni et al. 2002) and more significantly from 19.39 to 24.23 in chrF score (Popovic 2015).
|
Model / Evaluation |
Felatun Bey BLEU | Felatun Bey chrF | Ahmed Resmi BLEU | Ahmed Resmi chrF | Osman Agha BLEU | Osman Agha chrF |
| GPT-4 | 11.68 | 39.47 | 9.75 | 41.41 | 7.97 | 37.71 |
| GPT-3.5 | 11.14 | 38.09 | 8.23 | 38.58 | 7.11 | 35.84 |
| Gemini 1.5 * | – | – | – | – | 9.28 | 38.09 |
| Gemini 1.0 | 10.97 | 37.25 | 9.06 | 39.55 | 7.85 | 36.61 |
| Fine-tune (v1) | 10.94 | 33.52 | 3.29 | 23.24 | 2.78 | 20.07 |
| Fine-tune (v2) | 10.62 | 33.07 | 3.31 | 23.47 | 2.85 | 20.16 |
| Cohere Aya | 10.29 | 33.92 | 5.46 | 29.52 | 5.74 | 28.91 |
| Helsinki NLP | 9.74 | 33.25 | 3.44 | 22.21 | 2.83 | 19.39 |
| Multilingual Fine-tune † | – | – | – | – | 3.87 | 24.23 |
* We did not test Gemini 1.5 on these because the model was not released at the time of this study.
† No scores reported because we trained this model on Novel and Manuscript.
Concurrently, we tested OpenAI’s GPT-3.5, GPT-4, Google’s Gemini 1.0 and 1.5, and Cohere’s AYA models on the same test set using zero-shot prompting (Kojima et al. 2023) through API calls. Gemini 1.5 and GPT-4 were the best models, both with higher chrF scores than the fine-tuned NMT model, 38.09 and 37.71 respectively.
Our results led us to the second research question of this paper: how does the use of historical data in generative AI models complicate our understanding of the model performance? LLMs display great potential for translation of low-resourced languages, including those that were not seen in their training data (Tanzer et al. 2024). However, they are not consistent or reliable. Despite its impressive performance on OT, Gemini blocked the translation of several sentences from Osman Agha, ranging from 14 to 20% in different passes, citing safety blocks in 4 harm categories: hate speech, dangerous content, harassment and sexually explicit content.
We further investigated this response mechanism through Osman Agha. We hypothesized that depictions of warfare and violence in this account trigger the safety settings of Gemini. To further scrutinize the relationship between manuscript contents and safety blocks, we
acquired the German translation (Kreutel / Spies 1954) of Osman Agha’s memoirs and aligned it with the English translation to create a comparison set.
| Dataset Name | Number of Sentence Pairs |
| Ottoman Transliteration | 1,095 |
| English Translation | 2,191 |
| German Translation | 2,101 |
| OT-EN Parallel Text | 755 |
| DE-EN Parallel Text | 1,699 |
We prompted Gemini 1.5 through API calls, following a notebook published by Google (https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/getting-started/intro_gemini_1_5_pro.ipynb) and requested a translation of each sentence in OT and German. After a first pass, we identified the sentences without a translation and sent them again through the API. Each sentence that is marked as blocked in this paper, was blocked twice by the model.
| Category(ies) | Ottoman Turkish | German |
| Hate Speech | 0 | 7 |
| Dangerous Content | 6 | 19 |
| Harassment | 46 | 69 |
| Sexually Explicit | 36 | 110 |
| Hate Speech, Dangerous Content | 0 | 0 |
| Hate Speech, Harassment | 41 | 46 |
| Hate Speech, Sexually Explicit | 0 | 1 |
| Dangerous Content, Harassment | 21 | 34 |
| Dangerous Content, Sexually Explicit | 2 | 6 |
| Harassment, Sexually Explicit | 4 | 9 |
| Hate Speech, Dangerous Content, Harassment | 10 | 14 |
| Hate Speech, Dangerous Content, Sexually Explicit | 0 | 0 |
| Hate Speech, Harassment, Sexually Explicit | 6 | 6 |
|
Dangerous Content, Harassment, Sexually Explicit |
1 | 6 |
| All Four Categories | 1 | 0 |
| Total Number of Blocked Sentences | 174 | 327 |
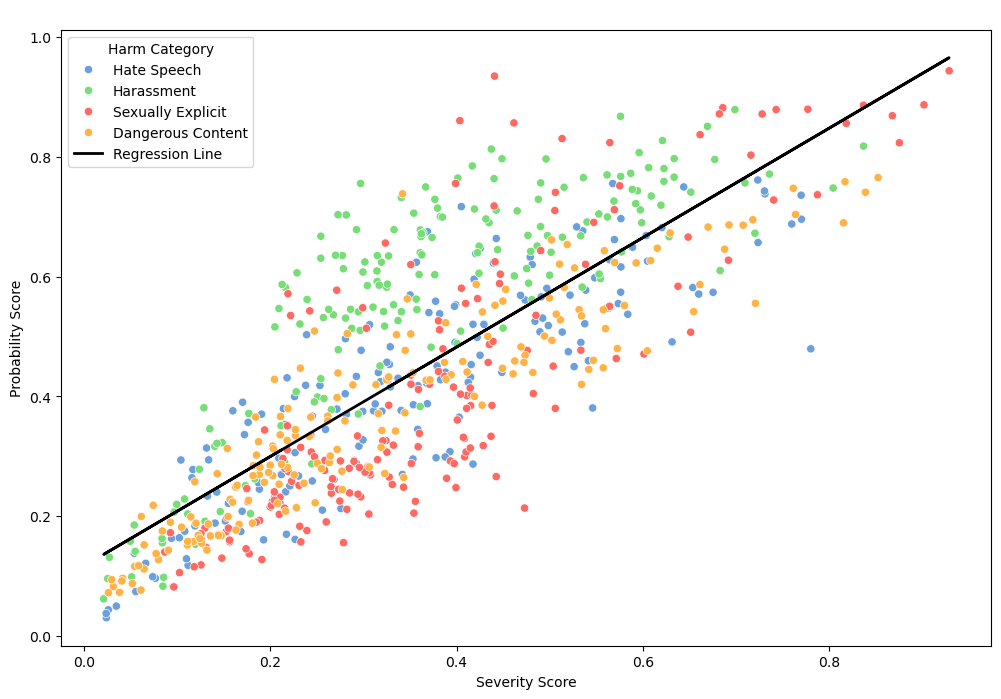
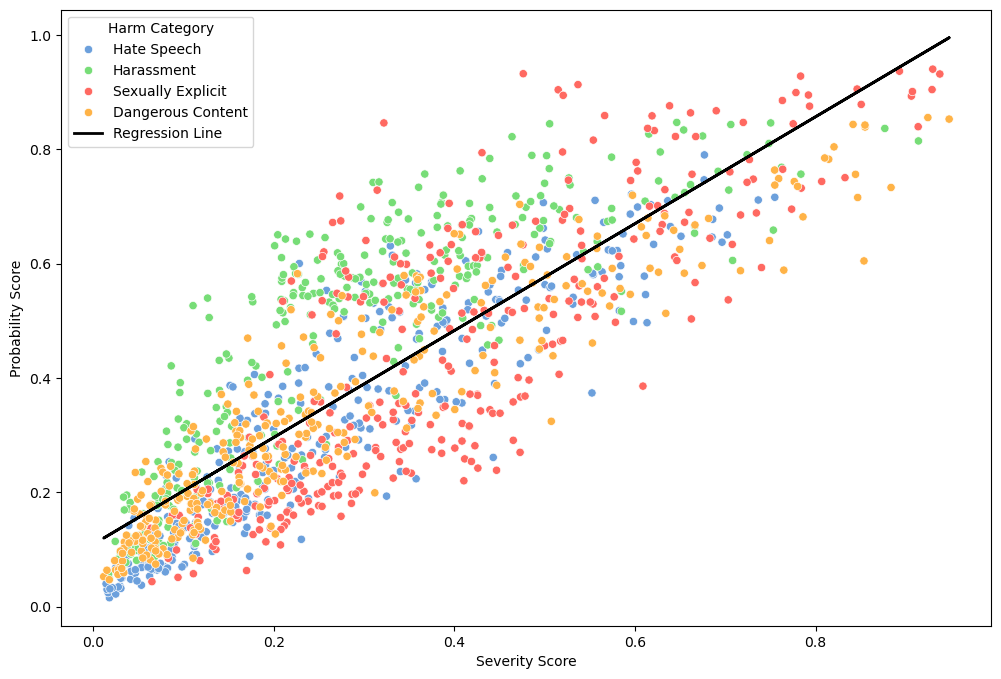
Plotting the blocked sentences shows that both OT and German texts are similarly processed by Gemini. This indicates that the blocking is not due to an issue with the low-resourced language but it indeed stems from the contents. Moreover, we can identify a relationship between severity and probability scores. Severity score measures how severe or extreme the harmful contents are. Probability score indicates how certain the model is of its classification. Increasing severity score strongly indicates an increase in model confidence for both OT and German cases, with a coefficient of 0.914 and 0.935 respectively.
Ottoman Turkish:
German:
Building upon research on content moderation with AI models (Gligoric et al. 2024), we argue that Gemini safety implementations fail to distinguish between use-cases of language, i.e. chat conversations and mention-cases, i.e. translations. This lack of distinction is dangerous when these models are deployed as translators 2 . Legal testimonies, educational materials, news reports, academic texts, and many others rely on accurate translation without content moderation. A report regarding assault should reasonably be expected to contain potentially harmful language, which nonetheless needs to be accurately translated. Studying how these models treat the translation of historical materials, we can infer and mitigate potential harms for contemporary societies. These models in many instances translate quite well but are coded not to without proper attention to the implications of these design decisions.
Ultimately, machine translation has always been and remains a complex social and technical task. By studying the specifics of translation from Ottoman Turkish to English, this paper draws connections between accessibility of non-English historical materials, inclusive pedagogies, limitations of AI, and mismatches between safety metrics and the real world use cases.
Tatoeba, a website that hosts crowd-sourced collections of sentences and their translation in multiple languages contains 2,381 example sentences for Ottoman Turkish (last accessed July 30, 2024, URL: https://tatoeba.org/en/sentences/show_all_in/ota/none ). We analyzed these examples and found them unreliable for our purposes especially considering there are also examples of translations from other languages into Ottoman Turkish. Ottoman Turkish is a dead language and as such it is hard if not impossible to evaluate the accuracy of translation into this historical language.
Google actively promotes the use of Gemini 1.5 for translation ( https://cloud.google.com/vertex-ai/generative-ai/docs/translate/translate-text ). There are 3rd party apps built with these models, such as: https://translate.hix.ai/ or https://chatgpt.com/g/g-5bNPpaVZy-translate-gpt and https://workspace.google.com/marketplace/app/translator_ai_gpt_chatgpt_gemini_transla/257171559362 .