Introduction
Emotion analysis in classical Chinese novels is worthy of in-depth research. Traditionally, analyzing such narratives has been the purview of human experts, whose subjective interpretations are integral to understanding the characters' emotional landscapes. Recent Natural Language Processing (NLP) and machine learning advancements enhance Large Language Models (LLMs), offering new ways to comprehend literary input contextually. These advancements enable automated emotion detection in texts, enhancing traditional character analysis with an objective and efficient framework. This research proposes an innovative LLM-based methodology for analyzing emotional character progression in Chinese fiction.
Sentiment analysis utilizes NLP to interpret emotional tones embedded in textual data, analyzing perspectives, emotions, or attitudes towards entities like products, services, or topics. The methodologies applied in sentiment analysis are diverse, encompassing rule-based strategies that employ predefined sentiment lexicons, machine learning models that learn from labeled data, and hybrid approaches that combine both (Wankhade et al., 2022). A comprehensive discussion on the technical and non-technical aspects of sentiment analysis, along with the presentation of challenges and potential directions for future research, has been highlighted in the context of big data (Shayaa et al., 2018). The capability of AI to identify and interpret emotions serves as an important benchmark for its efficacy in mimicking human cognitive functions.
This research introduces a novel methodology that utilizes large-scale generative language models to analyze the emotional shifts of its characters (Wang et al., 2023), particularly through their dialogues. This method is not complex, yet it can easily reveal the emotional trends of various characters throughout the story, significantly improving research efficiency. In the broader context of NLP, sentiment analysis stands as a crucial component. While sentiment analysis has been effectively used in literary studies, this research provides a fresh perspective on the emotional trends of characters in the Classical Chinese novel.
Corpus Overview: 'Jin Ping Mei'
In literary studies, extensive analyses have been conducted on numerous novels, exploring character development, plot construction and narrative strategies. ‘Jin Ping Mei’, dating from the Ming Dynasty (1368A.D. to 1644A.D.), is one of the classic Chinese novel (Hsia, 2016) . Its esteemed status in Chinese literature is further cemented by its inclusion in the “Four Marvelous Masterpieces ( 四大奇書 )” within Chinese literary history. This book is particularly lauded for its thematic exploration of human desires and complexities of morality, which are accompanied by rich emotional details of the characters, making it an exemplary subject for literary analysis and a prime candidate for our innovative sentiment analysis approach. The full name of the corpus is “Xiu Xiang Jin Ping Mei ( 繡像金瓶梅) ”, and it is sourced from Scripta Sinica (Institute of History and Philology, Academia Sinica, 1984) , a project dedicated to digitizing critical documents for traditional Sinology research.
Methodology
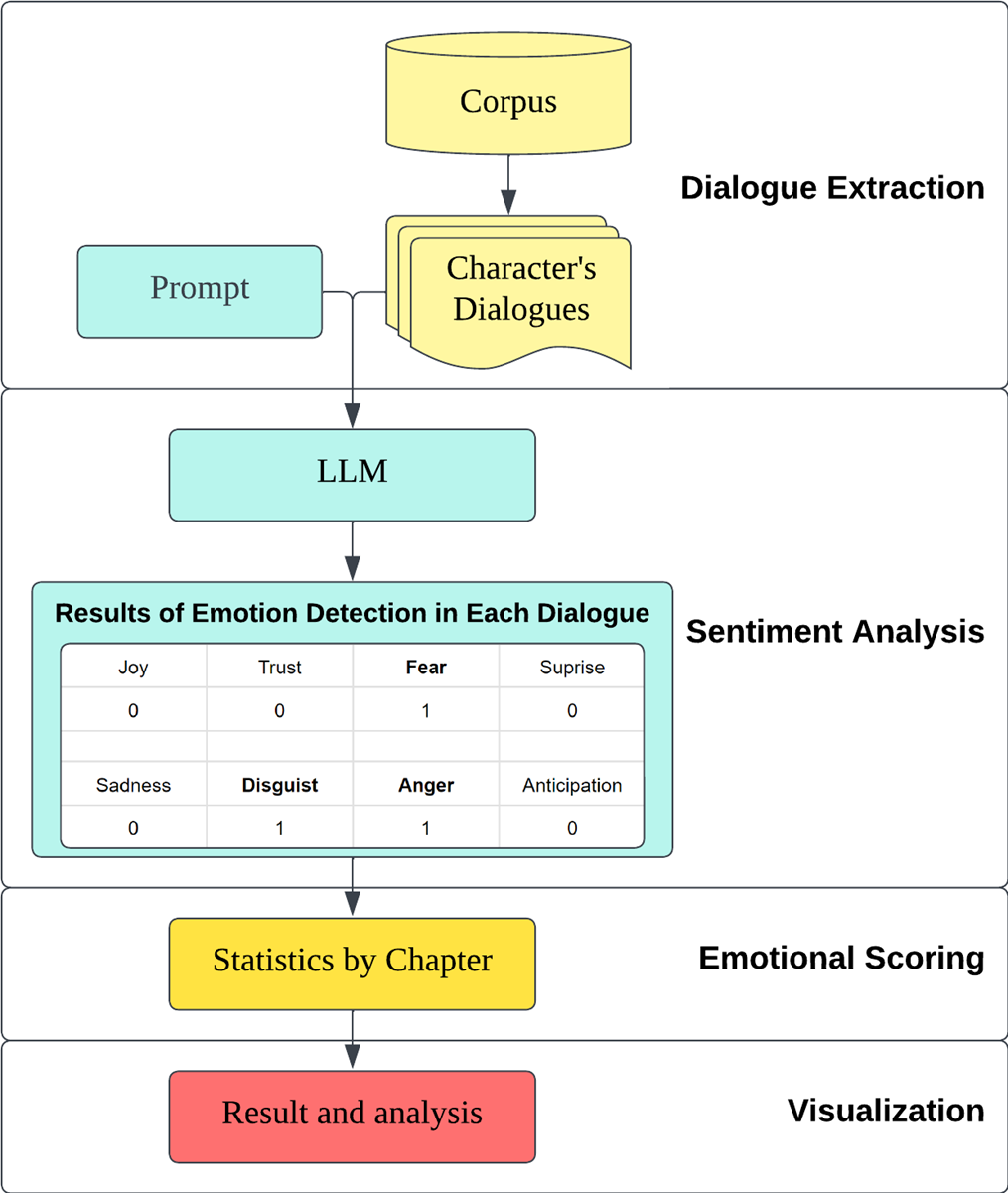
This research utilizes a character-centric analytical framework that meticulously surveys each persona within the novel’s narrative, focusing particularly on their dialogical expressions. The process (shown in Figure 1) can be divided into four stages: dialogue extraction, sentiment analysis, emotional scoring and visualization.
Dialogue extraction
Upon identifying a character within the text, we initiate a systematic procedure to extract their dialogical content from the entire corpus. The method hinges on detecting occurrences where the colon symbol (“:”)—indicative of character speech— is either immediately succeeded by or closely linked with the explicit citation of the character’s name. Although this strategy may not capture every dialogue instance, it proficiently retrieves most conversational exchanges. In this study, we specifically focus on the main character of the novel, Ximen Xing, to showcase the result.
Figure 1 : The methodology's flowchart : This methodology can be applied to various novels. Note that the quantity of character dialogues needs to be confirmed, more of dialogues can lead to more precise results.
Sentiment analysis with LLMs
As with adapted LLMs using ChatGPT (GPT-3.5-turbo-0613, which is affordable and highly capable) (OpenAI, 2023), the mechanism is designed to craft a prompt instructing the LLM to analyze the input texts. In response to the prompt, we then acquire the sentiment analyzing results. Therefore, the success of such analysis hinges not only on the prowess of the LLM but also on the design of the input prompts. Methodologically, the design decisions of the prompt (shown in Table 1) are rooted in achieving clarity, precision and consistency.
| the sentences I entered according to the following emotion categories: happiness, trust, fear, surprise, sadness, disgust, anger, anticipation | The emotional category |
| Use the number 0 to indicate the absence of the emotion and 1 to indicate the emotion is detected . | Binary rating system |
| It is forbidden to explain the reason for the rating, and it is forbidden to output anything other than the rating. It can only output 0 or 1. | Forbidden instruction for other in-between tokens influences the score |
| It is forbidden to explain the reason for the rating, and it is forbidden to output anything other than the rating. It can only output 0 or 1. | Forbidden message to prevent the additional cost from randomly generating tokens |
| The output should be presented in a comma-separated number format (EX: 0,0,1,1,0,0,0,1)." | Define output format. |
Table 1 : Structure of the final Prompt used
The first part of the prompts involves delineating specific emotion categories. We choose Plutchik's Wheel of Emotions as our emotion classification system, which was created by Robert Plutchik and categorized basic emotions into eight distinct categories, namely, joy, trust, fear, surprise, sadness, anticipation, anger, and disgust (Plutchik and Kellerman, 1980). This decision stems from the need to channel the LLM’s vast knowledge into targeted evaluations. Without such focus, an LLM might produce outputs that, while linguistically correct, might not be contextually precise.
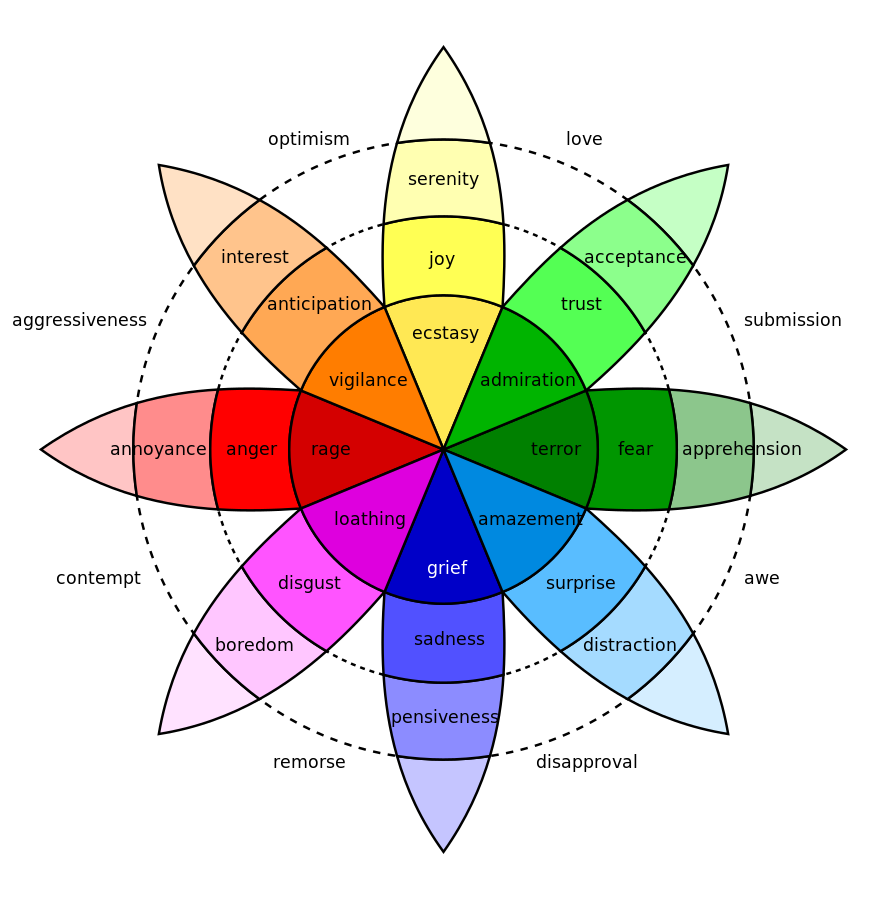
Figure 2 : Plutchik's Wheel of Emotions (Elf 1735, 2011) encompasses eight fundamental emotions. In our research, we use GPT-3.5-turbo-0613 to detect the presence of these emotions within the dialogues.
The second part of the prompts introduces a binary rating system to elicit an unequivocal response. By simply using “1” for presence and “0” for absence of an emotion, the approach reduces the margin for interpretative errors and offers a straightforward mechanism for subsequent data analysis.
To maintain the integrity of this data-driven sentiment analysis, strict instructions are embedded within the prompts. These instructions explicitly forbid the LLMs from explaining their ratings or producing any output beyond the binary ratings of 0 or 1. They ensure the model’s responses are consistent and strictly adhere to the task at hand without digressing into subjective interpretation or adding extraneous content. Additionally, this reduces the cost of additional tokens.
The final vital aspect of the prompt design is standardization. Defining a uniform output format, in our cases, a comma-separated sequence ensures every LLM response aligns with expectations. This is invaluable for scalability and integration with the next stage of systematically scoring the emotion for further analysis.
Emotional Scoring System
Building upon the prompt design detailed earlier, our Emotional Scoring System leverages the categorical clarity and binary rating mechanism to quantitatively assess sentiment. For each dialogue and each emotion from the set of emotions
,
the model returns a score such that:
Where indicates the absence of emotion in dialogue , and indicates the detection of emotion in dialogue . As previously described, this binary system simplifies interpretation and reduces error margins.
For each chapter , the emotional intensity score for an emotion , is calculated as the average of over all dialogues in chapter :
Where represents the set of all dialogues in chapter , and is the number of dialogues in chapter .
Thus, for each emotion in chapter , yields a value between 0 and 1, inclusive. This scoring system, grounded in the rigor of our prompt design, provides a standardized and scalable method for systematically analyzing emotional intensity across text segments.
Result and analysis
These emotional scores are graphically represented for analysis. The visual representation of the data is specifically designed to cater to three distinct analytical objectives, each tailored to derive specific insights. We refer to them as Emotion Spectrum Analysis (Figure 3), Focused Emotion Analysis (Figure 4), and Segmented Analysis (Figure 5). Additionally, the main character we picked, Ximen Xing, passed away in Chapter 80 of the story, so the emotional changes ceased after Chapter 80.
Overall, the presented figures illustrate the progression of Ximen Xing's emotions across each chapter. The line charts effectively demonstrate the complex interactions and gradual development of various emotions, providing insights into the nuanced and multifaceted nature of Ximen Xing as a Round Character (Forster, 1927, p.103). This analysis underscores the depth and intricacy of character development in the novel narrative.
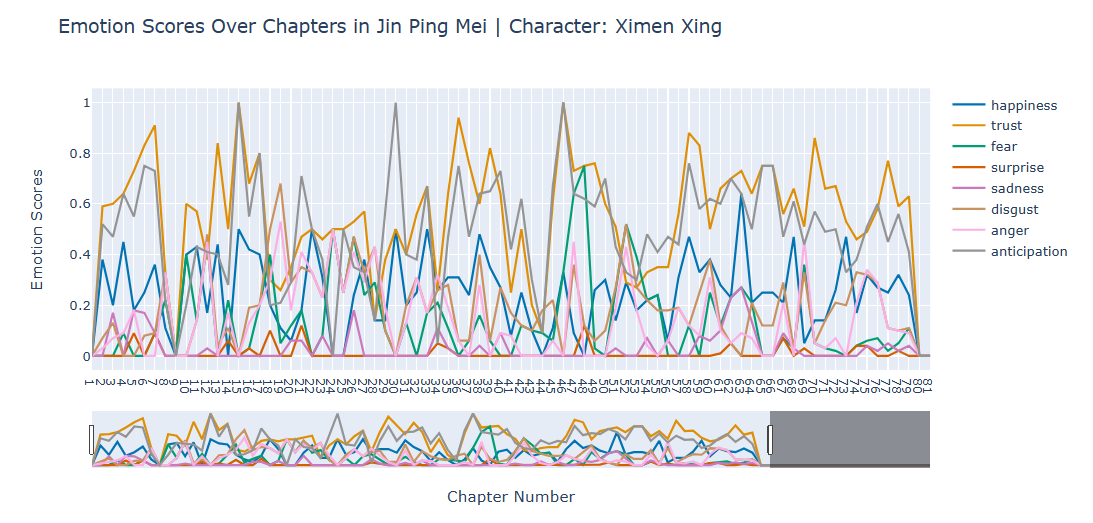
Figure 3 : Emotion Spectrum Analysis: The fluctuation in score of all eight emotions across chapters, with each emotion is represented with a distinct color. This enables an intuitive comparative analysis of emotional trends throughout the narrative's development.
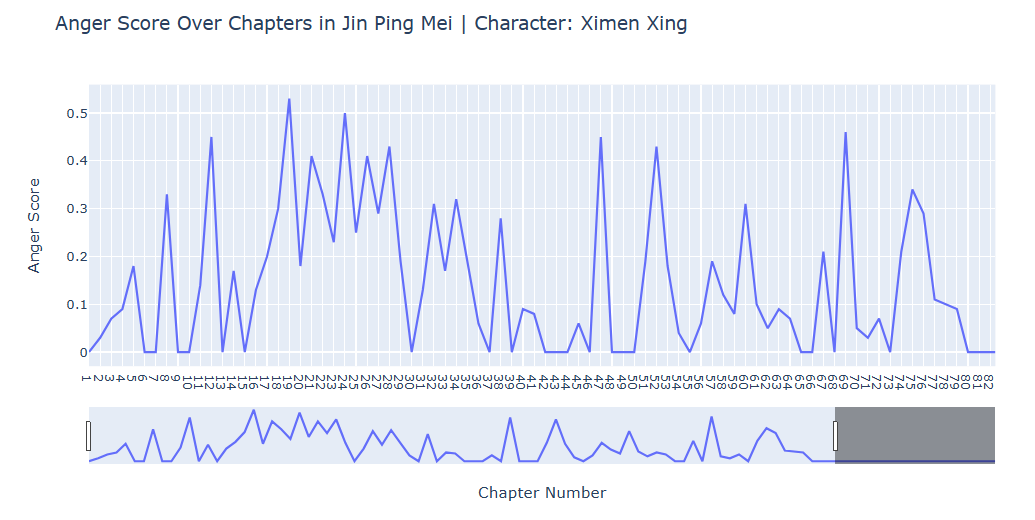
Figure 4 : Focused Emotion Analysis: We can observe the trend in focused emotion throughout the story, providing us with a deeper insight.
Simultaneously, the position of contrasting emotions throughout the novel (Figure 5), the Happiness scores tend to be higher than those of sadness, which hints at multifaceted situations in character, potentially indicating a generally positive or optimistic character arc. Swift, frequent shifts of the emotion scores might suggest a dynamic, action-driven storyline, whereas gradual fluctuations could indicate a more introspective or steadily evolving plot.
By visualizing such an intricate emotional alteration, the analysis accentuates the layered character development of Ximen Xing. This not only underscores the sophistication of the narrative but also the authenticity of its characters, allowing them to resonate profoundly with readers.
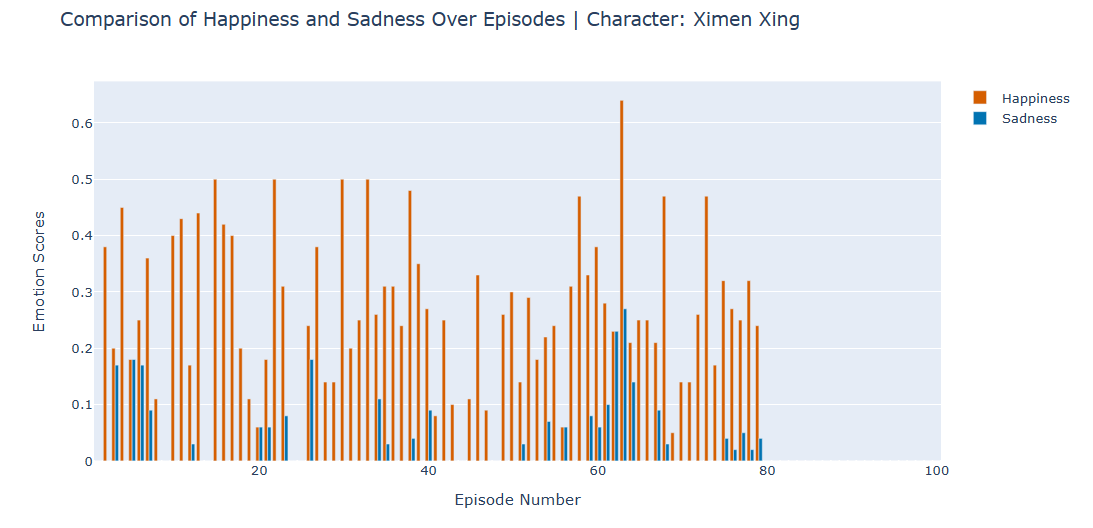
Figure 5 : Comparison of contrasting emotions: Comparing two different emotions allows us to discern the emotional conflicts the characters undergo in various chapters.
Conclusion
The visual mapping of complex emotional shifts highlights the intricate character development and plot arcs in Jin Ping Mei. This study pioneered a methodology combining sentiment analysis using LLMs, custom prompts, and emotion scoring to enable a broader analytical perspective. The streamlined process enables facile sentiment analysis applicable to diverse texts. Tracking emotional trajectories of characters throughout the narrative not only significantly reduces manual effort compared to previous approaches but also enables a wider analytical lens.
While scoring stability from LLMs and completeness of dialogue extraction remain limitations, this work demonstrates the potential of computational literary analysis to enable more objective, data-driven insights into emotion in classical Chinese literature. Further refinement of this methodology could profoundly enhance the depth of literary studies in this field. Since this research focuses on the development of the methodology, we have not compared the results across different large language models or between traditional models and large language models. These tasks are worth incorporating into future work.