Introduction
Digitally processing historical records in classical Chinese, such as the Ming Shi Lu, involves a series of structured steps, from digitalization to the intricate task of information extraction. The unique linguistic features of classical Chinese, characterized by nested structures and frequent use of synecdoche, pose distinct challenges. These are exacerbated by its tendency to omit subjects or objects in sentences. Traditional Named Entity Recognition (NER) algorithms, reliant on clear sentence structures, struggle with these complexities (Sasano & Kurohashi, 2008; Collobert et al., 2011), necessitating alternative approaches for accurate digital analysis of historical events.
In this context, the role of Large Language Models (LLMs) and prompt engineering becomes critical. LLMs can interpret the nuanced linguistic elements of classical Chinese, reducing reliance on extensive annotated datasets. This approach, coupled with targeted prompt engineering, enables more efficient training of NER models, specifically adapted to the subtleties of classical Chinese. Such advancements are vital for effectively digitizing and analyzing historical texts, providing a new dimension to digital humanities research.
However, challenges remain, including the need for high-quality annotated data to ensure comprehensive language representation (Ji et al., 2021; Ehrmann et al., 2023). The success of LLMs in this domain hinges on their ability to navigate the language's intricacies, offering a promising yet complex pathway for historical data analysis. As we digitize more historical archives, these AI-driven tools become indispensable in bridging the gaps in our understanding of history, while also raising important ethical and technical considerations for future research.
Methodology
Table 1 . The generic framework in this study
This research introduces a comprehensive framework using Large Language Models (LLMs) based on Generative Pre-trained Transformers (GPT) to address the challenges associated with annotated training data in classical Chinese for Named Entity Recognition (NER) tasks. The framework is methodically structured into two divisions, unfolding across three stages, as shown in Table 1:
Corpus Source
The Ming Shi Lu (明實錄 , the Ming Veritable Records) corpus, a comprehensive historical record of the Ming Dynasty provided by Academia Sinica (2013), is the primary source for our study. This corpus presents a diverse range of named entities, including the unique "Dusi-Weiso" military system, characterized by its distinct geolocation attributes (Tsai & Lai, 2017). This system poses a significant challenge in entity recognition due to its unique nature, making the corpus an ideal candidate for testing the effectiveness of generative AI.
Prompt Engineering
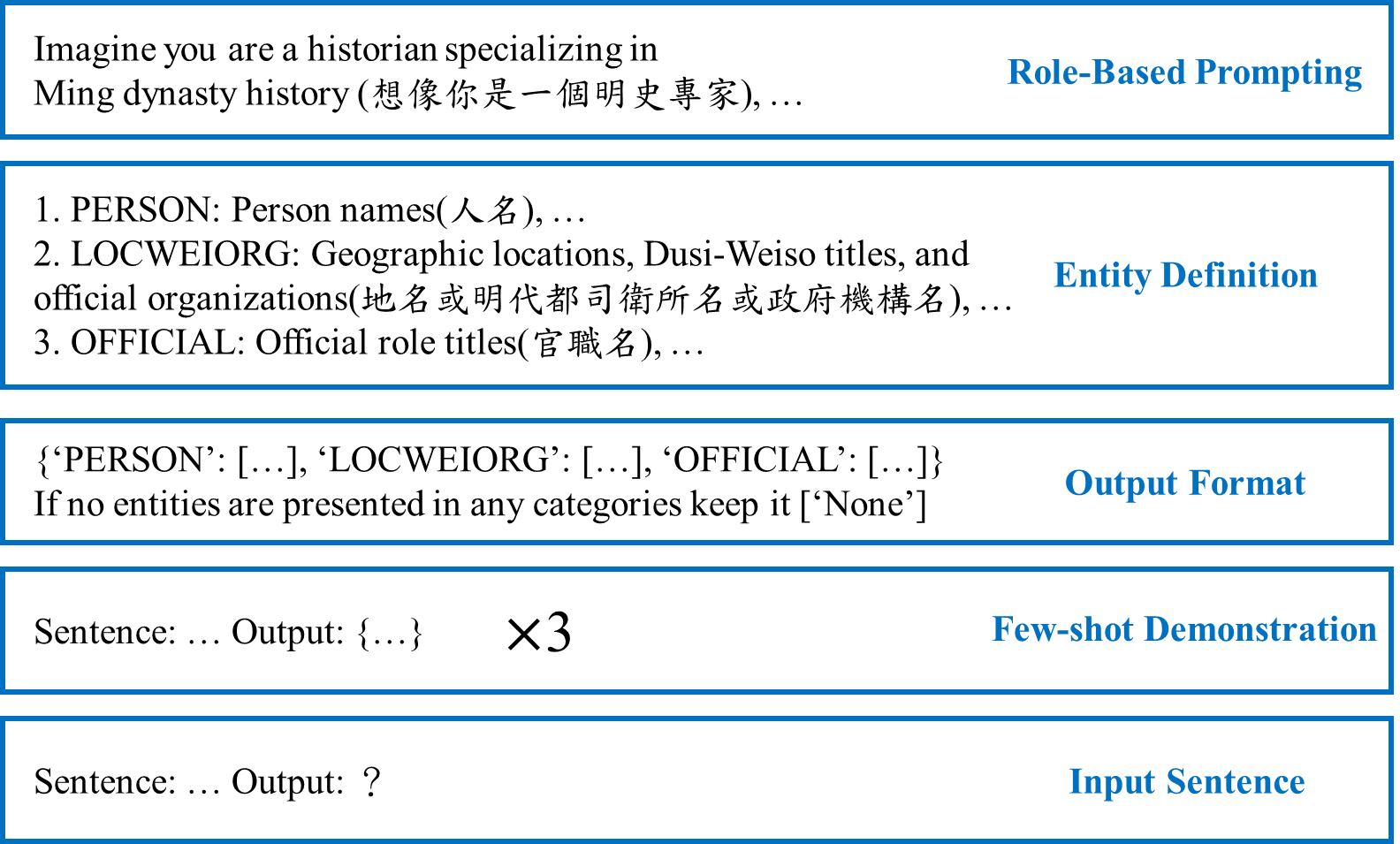
• Entity Definition: In this segment, we define the five named entity categories recognized by our model: Personal names (PERSON/PER), Geographic locations (LOC), Dusi-Weiso titles (WEI), Official organizations (ORG), and Role titles within official capacities (OFFICIAL/OFF).
• Output Format: Maintaining uniformity in the model's outputs is vital to prevent processing bottlenecks downstream. Therefore, our chosen output format emulates the Python dictionary style, ensuring consistency.
• Few-shot Demonstration: This component employs in-context learning (ICL), enhancing the model's predictive accuracy by providing relevant examples within the prompts. These serve as direct, task-related evidence that guides the model in generating more accurate annotations.
• Input Sentence: The final segment involves inputting the current sentence into the LLMs, prompting it to generate the desired output. This segment ensures that the model's focus is directed towards the specific text requiring annotation.
Figure 1 . An example of the prompt used in our framework
For the annotation task, we employed OpenAI's API for two versions of their GPT models: gpt-3.5-turbo-0613 and gpt-4-0613. Both models were subjected to the same set of prompts to evaluate their performance and compare their capabilities.
Knowledge-based Correction (KC)
The KC phase, a rule-based correction mechanism, is an integral part of our framework. It mitigates errors in LLM outputs by scrutinizing the model-generated output and applying specific rules to correct inaccuracies. This phase integrates the corrected annotations back into the original text, enhancing the integrity of the dataset for subsequent training, as shown in Table 2.
Table 2 . The effect of Knowledge-based Correction

Model Training
In the model training phase, 500 paragraphs from the Ming Shi Lu corpus were annotated using gpt-4-0613. Post-annotation, the KC was applied to refine the quality of the annotations, resulting in a high-quality training dataset. This dataset was then divided into training and validation sets at a 9:1 ratio. To further evaluate the model's performance, an additional 102 paragraphs were manually annotated to form the testing set, as detailed in Table 3.
Table 3 . The distribution of entities
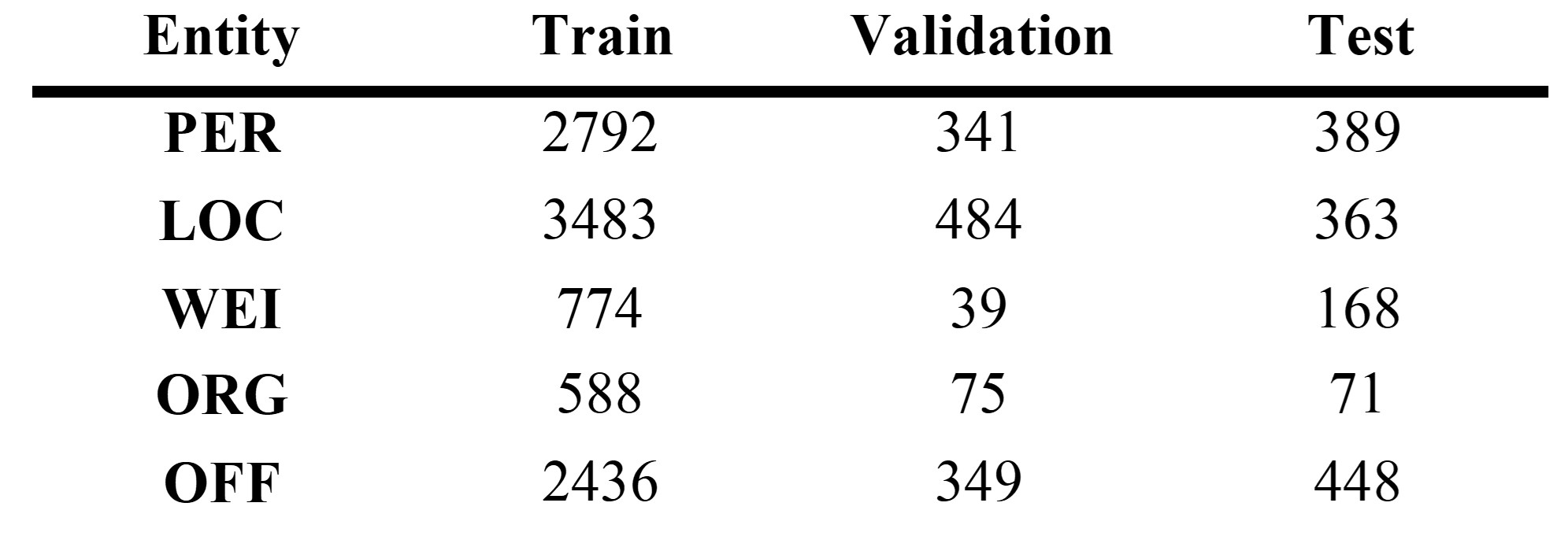
For training our model, we utilized flairNLP with the Jihuai/bert-ancient-chinese encoder, and a combination of Bi-LSTM and CRF for the decoder. This setup was chosen for its suitability in handling the specific requirements of ancient Chinese, aiming to achieve high levels of accuracy in NER tasks.
Our exploration into the capabilities of LLMs, specifically gpt-3.5-turbo-0613 and gpt-4-0613, focused on their effectiveness in NER tasks within humanities research. This process involves identifying and categorizing specific terms within texts—a critical component in many humanities projects.
Key findings from our study include:
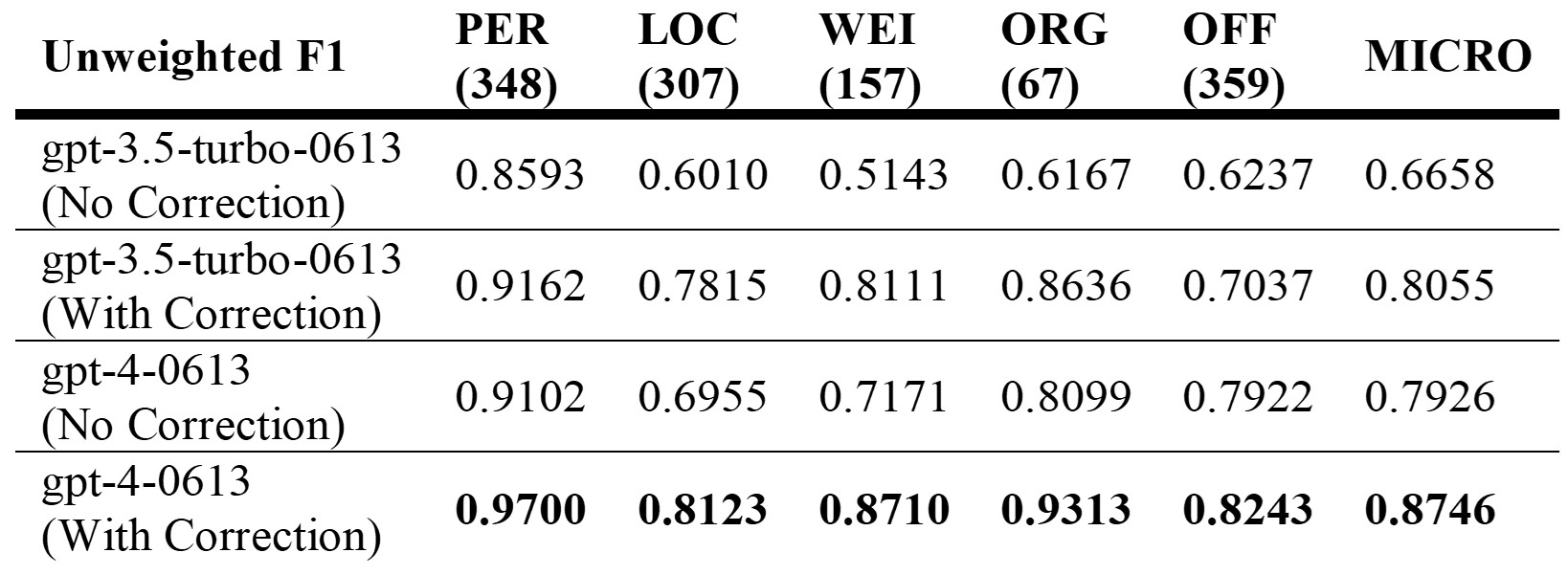
1. LLMs, particularly the newer gpt-4-0613, are exceptionally skilled in identifying person names. After applying the KC, gpt-4-0613 achieved an impressive F1 score of 0.97, indicating high accuracy in this task.
2. In a direct comparison, gpt-4-0613 displayed a distinct advantage over gpt-3.5-turbo-0613, particularly in uncorrected scenarios when identifying official titles.
3. The KC proved more impactful for gpt-3.5-turbo-0613, which occasionally confused different categories, such as locations and official titles. In contrast, gpt-4-0613 showed a more refined understanding and avoided these classification errors.
Table 4 . Comparison of unweighted F1 scores with and without Knowledge-based Correction in gpt-3.5-turbo-0613 and gpt-4-0613
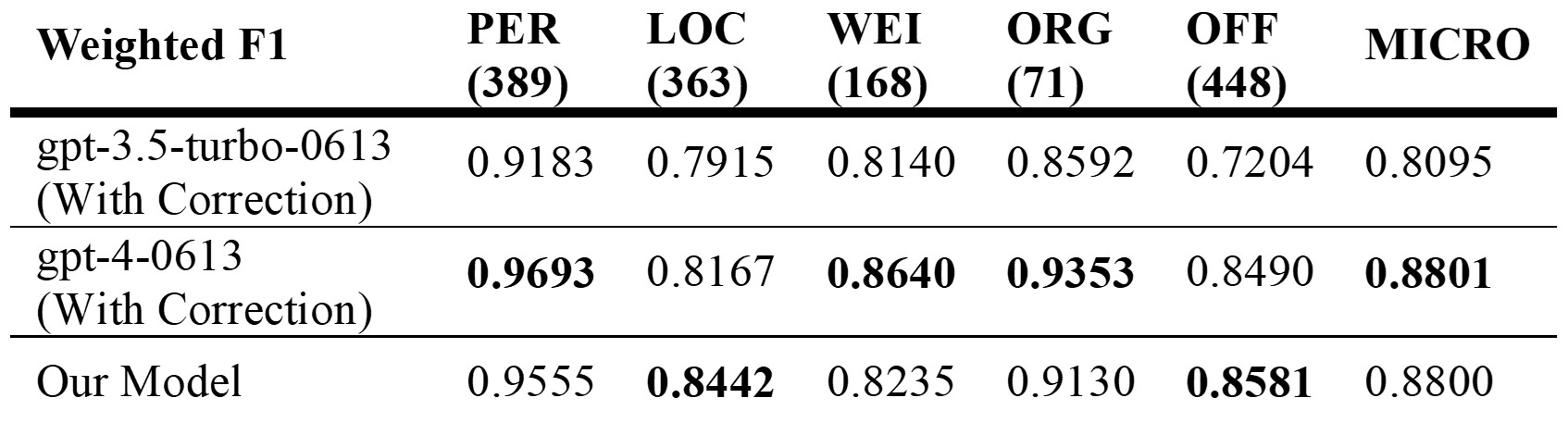
Guided by these insights, we employed gpt-4-0613 and the KC to create our training data, then trained our own NER models. A highlight was that our model, leveraging a dataset crafted by gpt-4-0613, matched gpt-4-0613's performance, thereby reducing our reliance on external tools for NER tasks.
Table 5 . Comparison of weighted F1 scores among gpt-3.5-turbo-0613 with correction, gpt-4-0613 with correction, and our model
This methodology demonstrates the potential of LLMs in enhancing digital humanities research, particularly in processing and analyzing historical texts. By effectively employing LLMs, coupled with precise prompt engineering and systematic correction methods, we showcase a significant advancement in the accuracy and efficiency of NER tasks within the realm of classical Chinese texts. This approach not only addresses the challenges posed by the lack of annotated training data but also opens new avenues for exploring historical documents through the lens of modern AI technologies.
Conclusion
Our study demonstrates a significant advancement in the integration of AI technologies with digital humanities, specifically in classical Chinese geographic entity recognition within the Ming Shi Lu corpus. By utilizing gpt-4-0613 alongside Knowledge-based Correction, we've transcended traditional NER methods, tackling the long-standing challenge of efficient annotation in digital humanities.
Key to our contribution is the development of a GPT-driven annotation dataset, available for academic exploration, and a state-of-the-art NER model, ready for further use and evolution in humanities research. These resources not only underscore the potential of AI in historical studies but also open avenues for broader applications and future scholarly work.
This research paves the way for readdressing historical academic challenges with modern technology, encouraging the academic community to engage with these tools for new discoveries. It marks a pivotal step in digital humanities, blending advanced AI with traditional studies to enrich our understanding of history.